Abstract
In today’s digital environment, computers cannot comprehend the human language we use on a daily basis. Humans and computer systems are unable to communicate effectively because of this. So, researchers came up with a novel method of obtaining data from digital machines. A branch of AI known as NLP has a significant influence on how computers and humans interact. Human-to-digital communication has been made much easier because of advances in natural language processing (NLP). To that end, this report examines the necessity for NLP technology in modern computing and the many techniques and applications that may be found within. Health care institutions may employ NLP to improve their competitiveness.
Introduction
Human language, as you are aware, is very complex. To comprehend this, a system must grasp grammatical rules, meaning, context, and slang and acronyms used in the language. Natural language processing (NLP) assists computers by simulating how people read and interpret language (Iroju & Olaleke, 2015). As presented by Iroju & Olaleke (2015). NLP is a vital discipline in which a system analyzes data and extracts information from settings. The system then displays the input data in a variety of ways. Natural language processing (NLP) is a method for computers to comprehend, interpret, write, or modify the natural language. The study of text and speech, on the other hand, is referred to as natural language. In comparison, a machine catches or identifies the meaning of input words via ordered output. Natural language processing is a critical part of AI. NLP was developed to enable individuals who do not know how to write computer code to get relevant information from a computer (Tvardik et al., 2018). Tvardik et al. (2018) confirm that in 1968, a film called “A Space Odyssey” popularized this kind of communication. NLP can also understand the information in emails, video files, and other unstructured stuff.
NLP may be applied in various ways in the healthcare business; however, these are just a few examples. These are things that can be checked. Treatment strategies are being put together to improve the patient’s experience. Many healthcare professionals and practitioners are using natural language processing (NLP) to assist them in making sense of the huge amounts of unstructured data included in electronic health records (EHR). This enables them to give their patients a more comprehensive level of care. It is estimated that the natural language processing (NLP) market in healthcare and the sector concerning matters of life will reach $3.8 billion by 2025, with a compound annual growth rate of 21 percent (Kocaman & Talby, 2021). In this essay, I will go into deep detail on the application of NLP in the healthcare field. In addition, I plan to learn more about NLP, how it operates, and how healthcare practitioners can benefit from this very wonderful technology in the future.
Problem
When an electronic health record’s usability is compromised, it takes longer to explore charts and input or retrieve data using typical keyboard and mouse interfaces (EHR). While EHRs promise to save and retrieve data fast and conveniently, they now suffer from usability issues that make them inefficient and unsatisfactory. These usability issues jeopardize a critical expectation for the EHR, which is that it should make it simple for people to swiftly obtain the information they need to give treatment (Kocaman & Talby, 2021). Because users were so worried about the usability of their EHRs, Meaningful Use incentives were diverted toward usability enhancements. Despite this, usability testing revealed that a large number of regularly used EHRs were not approved by the Office of the National Coordinator and failed to fulfill usability testing guidelines.
One usability issue with EHRs is the slowness of a keyboard and mouse navigating between interfaces and records. In a paper record, a clinician used to dealing with paper records may more rapidly locate and manually modify a patient’s list of medical concerns than in an EHR. Often, healthcare practitioners cannot utilize the EHR concurrently with patient care. Previously, Natural Language Processing Artificial Intelligence was employed to develop healthcare voice assistants capable of transcribing patient visit information into their electronic health records (EHR) (Kocaman & Talby, 2021). This technology is intended to reduce clinicians’ time on paperwork. This implies that professionals may devote more time and resources to direct patient care, which can help healthcare institutions become more efficient and sustainable.
Evidence
One solution would be to apply human-augmented machine learning to provide an informative, patient-specific story to address the issue. Natural Language Processing (NLP) can interpret the free-format text (also known as “unstructured data”) in Patient Notes and integrate it with the information contained in the tables and charts, resulting in a complete picture (the “structured data”). Work automation is seeing a significant increase in the employment and implementation of newly developed AI technologies to assist individuals in transitioning from paper to electronic records. In particular, this is true for those who work in the healthcare industry. Kocaman & Talby (2021) powerfully suggests that the use of a technology known as NLP may revolutionize how we handle and interact with patient information and enhance the way we care for individuals.
The information is stored in an EHR system at a more extensive scope. A patient’s information may be input into the EHR in one of four ways: by scanning documents, templates, using dictation or voice recognition, or by radiology systems, importing data from external data sources like lab systems, blood pressure monitors, or electrocardiographs. Data may be shown in either organized or unstructured formats depending on the situation (Tvardik et al., 2018). In order to be structured, information must be entered using a restricted number of options, such as drop-down menus, checkboxes, and pre-filled templates. One thing is undeniable: this is an excellent method for individuals to preserve their information. There is a great deal of data compression and loss of context, making them inappropriate for individualizing the EHR and too scattered for intelligent, holistic therapy, achievable with unstructured data, which is possible with structured data (Tvardik et al., 2018). They are simple to search for, collect, analyze, report on, and connect to other information resources because they are well-organized.
In contrast, unstructured clinical data may be available in free text tales, which are a kind of narrative format. Free-form clinical notes are often used to record interactions between providers and patients. It gives a practitioner greater flexibility to record observations and thoughts that are not supported or anticipated by the restricted options that come with structured data when a patient’s health record is filled up using free text. It is crucial to take notice of data that is intrinsically organized (Wen et al., 2019). Various other types of data, on the other hand, are not. At a more extensive scope, it is possible to achieve a satisfactory balance between NLP and free-form text. Some of the text narratives can be transformed into structured data, but the majority of the text may be left as free-form text, but with derived annotation and semantic analytics, allowing the EHR data to more closely resemble real-life circumstances in the future.
NLP systems have grown in popularity over the past several decades, despite the difficulty of implementing them in most hospitals. The words of Lavanya & Sasikala (2021) affirm that the market for NLP is developing steadily and is projected to continue to grow for some time, as indicated in the graph below.
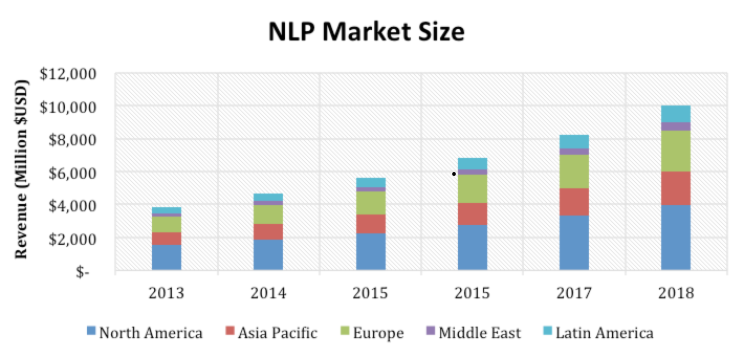
Figure 1: Sample Figure –NPL six years market size
Source: Chart Adapted from (Lavanya & Sasikala, 2021)
According to Lavanya & Sasikala (2021), the NLP market for health care and life sciences is predicted to increase at a 19.2 percent annual pace from USD 1.10 billion in 2015 to $2.67 billion in 2020. Based on the amount of money and the number of individuals who use them, Northern America has been predicted to be the biggest market for NLP solutions in the healthcare and life sciences business.
ANALYSIS
In the face of such a critical environment, the healthcare industry must act quickly to mitigate the negative consequences of the practices discussed thus far and increase their long-term sustainability. In this section, we’ll take a look at three different NPL applications in the hopes of coming up with a suitable/feasible solution:
NLP-Features Extraction Method
The similarity between two bits of text is measured using feature extraction techniques in NLP. Students of computer science and machine learning refer to this process as “natural language processing” (NLP). It ultimately boils down to writing computer programs that can comprehend various human languages. Natural language processing (NLP) refers to a computer’s capacity to interpret and read human language. Machine learning algorithms make predictions about the test data based on a compilation of variables in the training data. (Kocaman & Talby, 2021). They generate predictions about the test results based on these traits. It is difficult for machine learning algorithms to deal directly with raw text in language processing. Consequently, we need ways to transform the text into a properties matrix.

Figure 2: Sample Figure – Feature Extraction –
Source: Chart Adapted from (Wen et al., 2019).
The following are some of the most common ways to obtain features:
- The TF-IDF
- Bag-of-Words
The TF-IDF
TF-IDF highlights an issue that is critical while uncommon in our corpus. The TF–IFD value increases in proportion to the number of times a word appears in the text and decreases in the proportion of documents in the corpus that use the term. It is divided into two parts:
When a word is used a lot (TF)
TF: s Word frequency tells you how many times a term appears in the whole document. It could be thought of as the chance of finding a word in the text. There should be a relation between the number of words in the review and the number of times used. IDF: s. It is a way to tell if a word is unusual or common in the whole corpus. The inverse document function is a measure of this (Jiang et al., 2017). It looks for key phrases that appear in a small number of texts in the corpus. In simple terms, the rare words have a high rank.
Inverse Document Frequency
The score for IDF. IDF is a log-normalized figure calculated by taking the logarithm of the total number of documents with the term t and fractionating it by the total number of documents with the term D in the corpus.
Bag-of-Words
The following is a list of various phrases and expressions:
Using a Bag-of-Words approach is one of the most straightforward ways to turn a set of tokens into features. Words serve as features for the classifier to learn from when categorizing documents. On the other hand, negative reviews use words like “annoying” and “poor” in the review text if they appear in the review.
Using this model, it is impossible to tell the order in which words appear because we randomly place all of the tokens. That said, the world is not coming to an end as a result of this. Instead of looking at individual words, we can use N-grams (mostly bigrams) to figure this out (i.e., unigrams). This can help keep the words in their proper order in a given context. A table like this would look like this:
| good movie | movie | did not | a | … |
| 1 | 0 | 1 | 0 | … |
| 0 | 1 | 1 | 1 | … |
| 1 | 1 | 0 | 0 | … |
Figure 3: Sample Table – N-gram Matrix –
Source: Chart Adapted from (Wen et al., 2019).
Sentiment Analysis Using Natural Language Processing
Sentiment Analysis categorizes a piece of writing as either neutral, negative, or positive, depending on the author’s expressed thoughts on the issue. A text sentiment analysis system provides weighted sentiment ratings to each sentence or phrase for numerous elements, topics, themes, and categories using NLP and machine learning approaches. There are several ways to employ sentiment analysis in big enterprises, including market research, brand, product monitoring, and consumer feedback. Several data analytics firms are integrating third-party sentiment analysis APIs into their client’s social media monitoring platform, customer experience management, or workforce analytics platform in order to provide relevant information to their consumers.
This article will provide an overview of basic sentiment analysis as well as the benefits and drawbacks of rule-based sentiment analysis. Finally, we’ll go through some of the most typical applications for sentiment analysis before proposing some further resources. A document is dissected into its basic pieces to do text analytics. These sections are then examined using natural language processing to determine the content’s entities, topics, attitudes, and intentions (Davenport & Kalakota, 2019). Text analysis is a seven-step procedure. Sentence parsing includes Sentence Breaking, Sentence Chaining, Syntax Parsing, and Tokenization.

Figure 4: Sample Figure – Multilayered Text Deconstruction –
Source: Chart Adapted from (Wen et al., 2019).
In sentimental analysis, a sentiment library is used, which is a term that refers to a huge collection of adverbs and phrases that humans have assessed. These collections of words and phrases are referred to as “sentiment libraries (Jiang et al., 2017).” Everyone in this manual sentiment rating approach must agree on its relative strength or weakness to other ratings. The word “bad” has a negative sentiment score of -0.5, whereas the word “awful” has a value of -0.5. Your sentiment analysis algorithm interprets both terms negatively. Computer programmers create a set of criteria (called “rules”) that help the computer evaluate how people feel about a specific item (noun or pronoun) based on how close it is to either positive or negative phrases (adjectives and adverbs). A sentiment analysis engine that supports many languages must be able to accommodate different libraries for each language. Therefore, the libraries must be updated with new phrases, updated scores, and obsolete phrases. Software developers provide recommendations (called “rules”) to help computers assess how humans feel about a particular item (noun or pronoun) by comparing it to positive or negative phrases (adjectives and adverbs).
Utilizing an OCR system (Optical Character Recognition)
Health centers may use an OCR system to scan handwritten or typed text and convert it to an electronic representation. Accepted file types include Word documents and plain text files. You may, for instance, alter the document or incorporate it into another document. This method may now be used to modify the document file. When converting a paper document to an electronic format, which takes more time, OCR is used. It is often used to digitize printed books and papers.
Consequently, text mining, machine translation, and character and word recognition are all possible applications. Three essential OCR processing techniques are discussed in the following sections: Firstly, Pre-Processing: This step generates data that the OCR can analyze rapidly and accurately. Pre-processing is used to improve the image’s quality so that the system can recognize it more precisely. This procedure uses de-skew, binarization, line removal, and other techniques. Secondly, the character image is divided into its component components during the subsequent OCR processing step. According to Hudaa et al. (2019), this is critical because when an excessive amount of space separates the lines in the characters, the recognition rate falls. Lastly, Post-processing: is a step used to correct/detect errors and group data. Spell and grammar checks and comparisons to other specialist information sources assist in refining OCR results. When textual symbols are recognized, they generate a collection of distinct symbols.
Solution
| NLP Possible solutions | Pros | Cons |
| Extraction of features approach | Accurate in the analysis of similarities between text pieces. | Possible loss of word order as a vector of tokens is created in random order. |
| Sentiment analysis Approach | Classifies writing into the ether, negative, neutral, or positive. | During sentiment examination lexicon system is used, knowing that people express their emotions differently. |
| Optical character recognition approach | Time-saving, accuracy, and minimizes fatigue. | Requires highly skilled operators; other errors are unavoidable |
Figure 5: Sample Figure –– NLP suggested solution Approach
To provide high-quality results, healthcare natural language processing (NLP) systems must be customized for the task (Reeves et al., 2021), which requires time and effort. Due to the growing openness with which people communicate their thoughts and feelings, sentiment analysis is becoming a critical tool for monitoring and analyzing sentiment in all types of data. Consumer feedback, such as survey responses and social media conversations, may be automatically evaluated so that businesses can better understand what makes their consumers happy or annoyed and improve their products and services. Generally, being aware of customer needs and want gives a company a competitive advantage in its industry since what the company produces is what the customer demands in the market.
Conclusion
Artificial intelligence has the potential to transform healthcare delivery in resource-constrained countries. We may conclude that NLP is an effective method with specific features and a successful communication strategy, i.e., NLP is a set of tools and techniques of knowing that are utilized to accomplish goals and produce results during knowledge discovery. According to this study, artificial intelligence (AI) might be used to address and resolve a large number of health system challenges in these conditions. As a result of widespread smartphone use and greater investment in supporting technology, artificial intelligence (AI) may be used to improve public health outcomes in low-income countries (e.g., mHealth, cloud computing, and EMR). Even though we’ve shown how they’re being used to enhance health outcomes for people living in low-income nations, many more AI applications are being deployed today, and there will undoubtedly be more in the future years.
References
Iroju, O. G., & Olaleke, J. O. (2015). A systematic review of natural language processing in healthcare. International Journal of Information Technology and Computer Science, 8, 44-50.
Wen, A., Fu, S., Moon, S., El Wazir, M., Rosenbaum, A., Kaggal, V. C., … & Fan, J. (2019). Desiderata for delivering NLP to accelerate healthcare AI advancement and a Mayo Clinic NLP-as-a-service implementation. NPJ digital medicine, 2(1), 1-7.
Tvardik, N., Kergourlay, I., Bittar, A., Segond, F., Darmoni, S., & Metzger, M. H. (2018). Accuracy of using natural language processing methods for identifying healthcare-associated infections. International Journal of Medical Informatics, 117, 96-102.
Lavanya, P. M., & Sasikala, E. (2021, May). Deep learning techniques on text classification using Natural language processing (NLP) in social healthcare network: A comprehensive survey. In 2021 3rd International Conference on Signal Processing and Communication (ICPSC) (pp. 603-609). IEEE.
Kocaman, V., & Talby, D. (2021). Spark NLP: natural language understanding at scale. Software Impacts, 8, 100058.
Reeves, R. M., Christensen, L., Brown, J. R., Conway, M., Levis, M., Gobbel, G. T & Chapman, W. (2021). Adapting an NLP system to a new healthcare environment to identify social determinants of health. Journal of Biomedical Informatics, 120, 103851.
Hudaa, S., Setiyadi, D. B. P., Laxmi Lydia, E., Shankar, K., Nguyen, P. T., Hashim, W., & Maseleno, A. (2019). Natural language processing utilization in healthcare.
Jiang, F., Jiang, Y., Zhi, H., Dong, Y., Li, H., Ma, S. & Wang, Y. (2017). Artificial intelligence in healthcare: past, present, and future. Stroke and vascular neurology, 2(4).
Davenport, T., & Kalakota, R. (2019). The potential for artificial intelligence in healthcare. Future healthcare journal, 6(2), 94.
 write
write