Business Problem
Big data is used by many successful businesses to assess their progress and make important choices. Big data presents a significant challenge to organisations managing their staff and customers in estimating future performances, according to Singh and Singh (2019). An Apache Pig model offers a straightforward framework for developing workable solutions to common problems enterprises face. The study aims to provide a technical solution using the Apache Pig model for Amazon’s significant issue processing enormous data sets in their data bank. The Pig model suggests a systematic way for commercial businesses to handle enormous data. Therefore, an Apache Pig framework aids enterprises in condensing enormous data sets into information that can be handled and understood.
Large information technology companies are run globally. One of the biggest businesses in the sector is undoubtedly Amazon.com, Inc. of the United States. According to Niraula (2017), the international Company primarily focuses on cloud computing, e-commerce, digital streaming, and artificial intelligence. Amazon Inc. frequently encounters a big issue when managing the enormous amounts of data its users generate, despite its productivity and propensity to attract numerous customers (Soni and Uddin 2017). The Company needs the most pertinent client information to determine their preferences and develop the customer relationship. As an internet business, the organisation has access to vast consumer data, including their search histories, addresses, names, and purchases (Bhat 2019). As a result, the Company struggles to analyse the data in its data bank to enhance client interactions. Amazon must therefore launch the Apache Pig framework to facilitate easier access to and management of its customers’ information. Therefore, understanding a technological solution to Amazon’s issue using the Apache Pig model is essential.
Technical solution using the Apache Pig Model.
Amazon Corporation implemented an Apache Pig model to technically solve the big data problem. Gupta et al., (2020) established that an Apache Pig framework stipulates a practical assessment of an organisation using a structured query language (SQL) in its relational database management system (RDMS). The database management system provided a reliable method of retaining and recuperating extensive data collections while coalescing different tasks within the organisation’s design (Hewage et al., 2018). RDMS embraced processes that supported data control, consistency, accuracy, and information safety (Rashid and Huang, 2021). Amazon Corporation needed to transmute its data evaluation process by implementing an effective change plan. The Apache Pig consisted of three stages that assisted Amazon in programming its data bank system to hold ample information using understandable and straightforward codes (Tang et al., 2020). First, the model embraced a programming process that entailed encoding and scripting large data sets. Second, Pig included a planning process of transforming information into simple information by compiling and reducing it. Third, Apache Pig executed reduced transmission to obtain the desired outcome. Easy data encryption helped maintain data for a significant period and recover information at any given time.
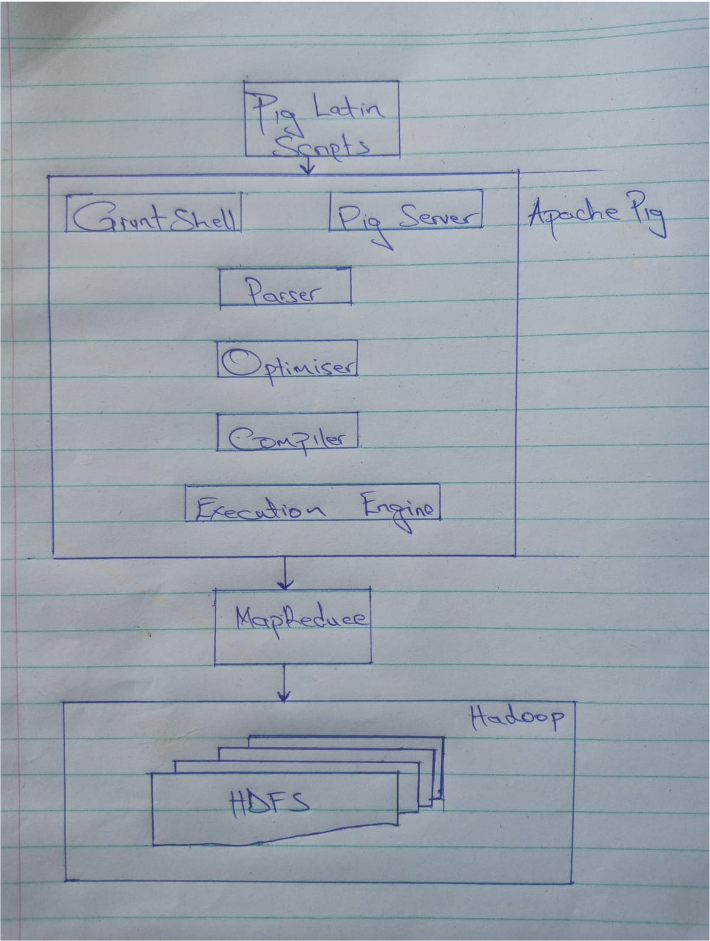
Amazon Corporation implemented an Apache Pig model to technically solve the big data problem. The process began with extensive data collection, including customer information, product data, sales records, and other relevant datasets (Volk et al., 2020). In the first stage, the Apache Pig model assisted in programming the data bank system using understandable and straightforward codes, particularly utilising the Pig Latin Program (Singh et al., 2022). This step involved encoding and scripting large data sets to prepare them for further processing.
After the programming phase, the Apache Pig model entered the planning stage, which consisted of two sub-stages: the logical plan and the physical plan Muniswamaiah et al., (2019). In the logical plan, a plan was created to validate all the encrypted information, ensuring that only authentic data was retained while disregarding invalid customer data to maintain data accuracy and control. Assenting to Soni and Uddin (2017), the logical planning process also facilitated obtaining detailed customer thoughts regarding Amazon’s services, contributing to better decision-making. Subsequently, the logical plan transformed into a physical planning process, where the validated information was processed and compiled into the Company’s system (Niraula, 2017). The physical plan organised the data for easy mapping and reduction of authentic customer data.
The planning process led to the MapReduce planning phase, where mapping and reducing operations were applied to the compiled and validated data (Giménez-Alventosa et al., 2022). The mapping process grouped amassed data based on various attributes such as locations, races, ages, gender, or occupation, enabling Amazon to differentiate different categories of data for easy assessment and analysis Talha et al., (2020). In the reduction process, information was sorted, and tasks were assigned to several departments within the organisation to easily manage related databases, effectively distributing the organisation’s workload within the mapped groups and enhancing efficiency (Hewage et al., 2018).
Finally, the Apache Pig model executed the reduced tasks using the Hadoop model, which stored information in the Hadoop Distributed File System (HDFS). China et al., (2019) articulated that the Hadoop MapReduce framework efficiently processed extensive data by distributing computation across a cluster of machines. The MapReduce and Hadoop execution resulted in relevant outcomes that provided insights into the organisation’s strengths and areas requiring changes for better service provision. These insights played a crucial role in data-driven decision-making processes within Amazon Corporation (Bhat 2019).
To sum it all up, the Apache MapReduce architecture implemented by Amazon Corporation using Apache Pig involved a series of stages, starting from input data and progressing through programming, planning, MapReduce, and Hadoop execution (Vassakis et al., 2018). The architecture efficiently handled and processed extensive data collections, providing the organisation with valuable insights to address their big data problem and make informed decisions.
Conclusion
In conclusion, the paper extensively expounded on the significance of adopting an Apache Pig framework in determining a technical resolution to any glitch a business encounters regarding extensive data systems. Amazon Company’s big data challenge was handling its customers’ complex information, which was widely distributed internationally. The Apache Pig framework postulated a systematic structural procedure for practically solving the organisation’s problem. The framework’s assessment approach involved encrypting massive data sets by initiating a Pig Latin Program. The program simplified the data using simple codes that Amazon could control and understand. Thus, information was easy to keep and restore within the system. Besides, the model’s planning stage presented a three-phase plan. A logical plan validated data, and a physical plan compiled the valid information, while a MapReduce plan mapped and reduced the gathered data. Ultimately, a Hadoop execution followed the planning process to pave the way for the organisation’s decision-making process.
References
Bhat, A., 2019, December. An analysis of crime data under apache pig on big data. In 2019 Third International Conference on I-SMAC (IoT in Social, Mobile, Analytics and Cloud)(I-SMAC) (pp. 330-335). IEEE.
Chiniah, A., Chummun, A. and Burkutally, Z., 2019, September. Categorising AWS Common Crawl dataset using MapReduce. In 2019 Conference on Next Generation Computing Applications (NextComp) (pp. 1-6). IEEE.
Giménez-Alventosa, V., Moltó, G. and Caballer, M., 2019. A framework and a performance assessment for serverless MapReduce on AWS Lambda. Future Generation Computer Systems, 97, pp.259-274.
Gupta, Y. K., & Mittal, T. (2020, November). Comparative Study of Apache Pig & Apache Cassandra in Hadoop Distributed Environment. In 2020 4th International Conference on Electronics, Communication and Aerospace Technology (ICECA) (pp. 1562-1567). IEEE.
Hewage, T.N., Halgamuge, M.N., Syed, A. and Ekici, G., 2018. Big data techniques of Google, Amazon, Facebook and Twitter. J. Commun., 13(2), pp.94-100.
Muniswamaiah, M., Agerwala, T. and Tappert, C., 2019. Big data in cloud computing review and opportunities. arXiv preprint arXiv:1912.10821.
Niraula, N. (2017). Web Log Data Analysis: Converting Unstructured Web Log Data into Structured Data Using Apache Pig.
Rashid, A. and Huang, C.Y., 2021. Sentiment Analysis on Consumer Reviews of Amazon Products. International Journal of Computer Theory and Engineering, 13(2), p.7.
Singh, A. P., & Singh, G. (2019). Analysis of Amazon Product Reviews Using Big Data-Apache Pig Tool. International Journal of Information Engineering and Electronic Business, 10(1), 11.
Singh, A., Shukla, V.K., Seth, A. and Sabitha, S. eds., 2022. ICT and Data Sciences. CRC Press.
Soni, J., & Uddin, I. (2017). An Hybrid Product Recommendation Model Using Hadoop Server for Amazon Dataset. Advances in Computational Sciences and Technology, 10(6), 1691- 1705.
Talha, M., Sohail, M. and Hajji, H., 2020. Analysis of research on Amazon AWS cloud computing seller data security. International Journal of Research in Engineering Innovation, 4(3), pp.131-136.
Tang, S., He, B., Yu, C., Li, Y. and Li, K., 2020. A survey on spark ecosystem: Big data processing infrastructure, machine learning, and applications. IEEE Transactions on Knowledge and Data Engineering, 34(1), pp.71-91.
Vassakis, K., Petrakis, E. and Kopanakis, I., 2018. Big data analytics: Applications, prospects and challenges. Mobile big data: A roadmap from models to technologies, pp.3-20.
Volk, M., Pohl, M. and Turowski, K., 2018. Classifying big data technologies-an ontology-based approach.
 write
write