Abstract
Supervised Machine Learning is a machine learning technique that helps in capturing the knowledge regarding input/output relationships that are present in the training set, also known as a specified set of pairs of the training sample. Due to the fact that the output data is utilized to monitor labels throughout the training sample operation, these training samples are also regarded to be training data or monitored data. It is often regarded as the finest tool for making data-driven choices. Inductive machine learning is used to process labeled data, also known as learning data. Additionally, persistent learning is employed to forecast the output outcomes of the system. The primary goal of Supervised Learning is to develop a computer system capable of forecasting the results of learning events. Supervised learning enables the examination of the links between input and output in order to construct an artificial intelligence-based system. By giving a restricted collection of discrete values, an algorithm may be trained to appropriately classify the input. As a result, the input values will be associated with the output values, which will be in the form of continuous data. As a result, this study will concentrate on the influence of supervised machine learning on cloud computing. The purpose of this study is to develop a function that aids in forecasting the outcome of an experiment using training data from the inquiry. Projected continuous values, also called regression, could be provided by the procedure; however, it depends upon the function being used, which is called classification. Based on several training examples, guided learners make predictions, and many students and teachers are working together to make such predictions a reality. Neural networks and support vector machines are the two most popular categorization methods in cloud computing. Through cloud computing, networks, servers, storage, and applications are all easily available and accessible. This term has gained popularity in recent years in customer service relationships (NIST).
Introduction
Although grid computing, utility computing, cloud systems, virtualization, and other well-established methodologies are not new technology, they are part of a paradigm that unifies them into a cohesive whole. Using cloud computing systems makes it feasible to spread resources such as scalable infrastructure, middleware, application development platforms, and high-value commercial applications to several locations [1]. A core service layer is composed of three components: Besides these two components, PaaS (Platform as a Service) and Infrastructure as a Service (IAAS) are also available (IaaS). A cloud-based software service, often known as a SaaS, enables users to access vendor programs housed on cloud infrastructure, such as Salesforce.com, without downloading and installing the software (SaaS). Specific applications may be accessed using thin client interfaces such as a web browser (such as web-based e-mail) or programmatic interfaces, which may be accessed from several client devices in some instances. Consumers have access to a cloud infrastructure, except for a limited number of restricted users who have access to the underlying cloud infrastructure, which is already in existence [2]. This infrastructure includes networks, servers, operating systems, storage, and specific application capabilities. There is just no way to deal with or regulate it at all. In general, the program’s options may be found here (NIST). Platform as a Service allows customers to run their own or bought apps on a cloud infrastructure by employing programming languages, libraries, services, and tools provided by the service provider. This is referred to as Platform as a Service. In a way, this is an homage to the original [3]. Customers may be able to control the deployment of programs and the application-hosting environment (including networks, servers, operating systems, and storage) rather than the underlying cloud architecture in certain circumstances [4]. It is possible to install any software on a computer’s hard drive since the computer can provide users with the required computing capabilities. This includes operating systems and apps, among other things. Infrastructure as a Service (IaaS) is an acronym for Infrastructure as a Service. Instead of managing the underlying cloud infrastructure, consumers have complete control over the operating system, storage, and installed apps. Limited control over various network components and specific network components is possible (NIST’s) [5]. The cloud computing environment offers users access to many different resources at their disposal [6]. It would help if you first determined how much CPU time, disk space, memory, and network bandwidth your program requires to make the most effective resource allocation decisions before assigning resources. Because cloud service providers are aware of the number of resources, they are using, optimizing their operations is helpful [7]. Cloud computing is the resource allocation that provides Internet resources to cloud apps to perform their functions. If resource allocation is not managed correctly, the potential of running out of services exists. Resource provisioning is used to overcome this issue by granting control over resources to the service provider for each module [8] [9]. It is essential to avoid the following characteristics while designing resource allocation techniques for optimization. It is called resource contention when there is a more significant demand for shared resources than the supply of those resources. These resources include memory, CPU, network, and storage. Resource contention is a critical challenge because cost-cutting is at the heart of current information technology [10]. The primary cause of worry regarding resource contention is the possibility of a decline in performance due to the circumstance.
The second criteria to consider is financial restrictions. As a result of the fact that there are only a limited number of resources accessible and a high demand for those scarce resources, this situation occurs [11]. In this case, the user cannot access the shared resource due to technical limitations. Resource fragmentation (also known as resource segregation) separates resources within a specific geographic region to round out the definitions [12].
As a result of the system’s fragmentation, resources would not be allocated appropriately to the appropriate application in the future. We will only be able to harness the full potential of fragmentation if we work together as a group of large enterprises. Remember that over-provisioning, which happens when an application receives more resources than requested, is also something to keep in mind. The high levels of investment and low levels of revenue help make up for part of the income gap. The last kind of under-provisioning occurs when an application is provided with fewer resources than it requested [13]. A Kenyan-owned and operated company Safaricom Limited, a Kenyan firm that provides cloud computing services, was founded in 2011 [14]. The ability to eliminate the need to invest in and maintain physical infrastructure on their premises, such as file and e-mail servers, storage systems, and software, is a significant advantage of cloud computing for businesses of all sizes. Simple web applications made possible by the availability of these information technology resources may increase productivity, which can be accomplished via these resources [15]. Safaricom provides a wide range of cloud services, including Infrastructure as a Service (IaaS) and Software as a Service. Platform as a Service, Hosted Applications, Software as a Service, Data Archiving, Backup and Recovery, and various other services are available. Identifying and mapping resource utilization patterns of clients against available resources is essential for any organization involved in cloud computing service delivery to justify their claims when advising clients on their actual cloud resource requirements [16]. This will improve cloud computing resource management by allowing them to justify their claims when advising clients on their precise cloud resource requirements [17]. Cloud service providers will be better equipped to plan for their available resources in the most efficient way possible if consumers supply them with exact information about their particular resource requirements. This will result in lower prices for customers.
Research Goal and Objectives
This paper aims to develop machine learning algorithms to predict how much clients will use cloud storage resources. It’s critical to have clear objectives in mind. Specifically, the study examined the following areas: Lists of machine learning approaches currently in use are being put up right now. Artificial intelligence technology has never been as accessible as it is now. In this section, we will examine three machine learning techniques, including linear regression and support vector machine, and the metrics used to evaluate them will be mean absolute percent error, root means square error, coefficient of variation, and a comparison between actual and predicted data sets. We need to start preparing for efficient resource delivery and distribution as soon as possible based on some type of forecasting or prediction process, given how rapidly cloud computing is taking form throughout the globe. We anticipate that cloud computing resource management applications and cloud service providers, such as Safaricom Ltd.’s cloud infrastructure service, would be able to use the most effective machine learning technique for forecasting resource demand (Cloud IaaS). This paper demonstrates how machine learning may be used to forecast cloud storage resource use. Based on the study’s findings, SVM was determined to be the optimal approach for the scenarios examined.
Review of Literature
In this part, we review what has been updated. The employment of artificial intelligence apparatuses and calculations, asset utilization profiling, and other pertinent duties are described throughout this presentation. The three primary administrations in cloud computing are PaaS (Platform as a Service), SaaS (Software as a Service), and IaaS (Infrastructure as a Service) (Infrastructure as a Service) [18]. For the time being, there is no effective artificial intelligence solution for IaaS cloud computing management that can estimate the usage of capacity assets. By using artificial intelligence, it is possible to evaluate these capacity assets based on the designs of prior customers (AI) [19]. There are various ways and parties engaged in making it possible when it comes to cloud computing administration. Each of them was thoroughly investigated and analyzed as part of the survey [20][21] [22]. Exploring a diverse range of models is required to understand better the various assets available and the tactics utilized to divide these assets among different groups of people. An investigation of artificial intelligence calculations and display techniques, their advantages and disadvantages, and the potential applications of these methodologies is carried out for this goal [23]. This approach may be used to understand better how to spend resources for the association’s future predictions by analyzing historical data. Clients may save money by using cloud registration administrations, which may lower expenses while also alerting them to possible needs before they exist if required [24]. Throughout the previous decade, the field of assessment has been dominated by the adverse effects of factual assessment approaches, which have been widely used. Because of their incapacity to deal with large amounts of raw data, adapt to missing elements, or disseminate components over a large geographic area, investigations including non-conventional approaches such as artificial intelligence procedures have increased in popularity in recent years [25].
Artificial intelligence systems seldom include concepts like human-created reasoning, data hypothesis, computational complexity, control hypotheses, and theory. Specifically, the scientist for Safaricom Limited, a local cloud computing specialist co-op that supplies this form of assistance, and the strong associations that Safaricom Limited serves as customers for their instance of Infrastructure as a Service reached a choice. If a cloud expert cooperator fails to effectively use the resources at his disposal, the cloud client may be forced to pay for services they do not genuinely need. Both the customer and the specialized cooperative may suffer due to excessive expenses [26].
Using cloud computing, it is now possible to have on-demand access to a shared pool of customizable assets (e.g., servers, storage, and software) that may be promptly supplied and delivered with minimum administrative work or coordination across specialized organizations. Among other things, this cloud model comprises self-administration on-demand (Broad access, Resource pooling, Rapid adaptation, and Measured Service), three assistance models (Cloud SaaS, PaaS, and Cloud Infrastructure as Service), and four sending models (Private cloud, Community cloud, Public cloud, Hybrid cloud) [27]. It is widely acknowledged that the virtualization of ware equipment is one of the most critical developments in the field. It allows for a high level of performance while also lowering costs and improving efficiency (NIST). We’ll go through several models for cloud-based registration management in this section. The usage of assistive technology is becoming more common (SaaS). It is made possible for the buyer to take advantage of the cloud-based apps made available by the service provider. Instead of a traditional user interface, a primary user interface such as an internet browser (for example, online e-mail) or a program interface is used to access the apps via several consumer devices [28]. Aside from a few limited client-specific application configuration choices, there is no control over the cloud’s fundamental underpinnings, such as the cloud’s network or servers or even individual applications (NIST). As a platform-based service provided by (PaaS), a cloud-based platform may be used to host applications that have been developed or bought by customers using programming languages, libraries, administrations, and devices that the provider has authorized. As a platform-based service provided by (PaaS) [29].
It is conceivable for a client to have some level of control over the provided apps and the environment in which they are executed while having no control over the underlying infrastructure of the cloud (NIST). The following are some of the benefits of PaaS: It is feasible to develop applications more quickly and advertise them more effectively than ever before. With the help of middleware, new web applications may be swiftly deployed to cloud environments. Operating systems and applications that assert their existence may be managed stored, organized, and worked with the assistance of infrastructure (IaaS). Customers have only rudimentary control over the operating systems and storage of the cloud foundation, and they may have only limited control over some systems administration components of the cloud foundation (NIST) [30].
Amazon SimpleDB, non-social information storage, allows quick and easy access to and customization of large data sets. Designers use web service requests to store and query data and Amazon’s SimpleDB. SimpleDB’s accessibility and flexibility have been significantly improved, allowing it to be used outside a social data collection context. Thanks to Amazon SimpleDB, you can be sure that your data is being stored in various locations across the world while you are at work, which handles everything for you. Customers are only paid for the resources used to store and fulfill their requests, not for the time it takes to do so. Any time a client requests a modification to your system’s model, the system’s model is immediately updated [31] [32]. Instead of becoming bogged down in constructing frameworks, ensuring high user accessibility, maintaining programs, developing and documenting the board, and adjusting the execution, clients may concentrate on application development [33]. Amazon SimpleDB offers several benefits for storing information logs, including the following: To obtain all of your customers’ information records, you won’t have to wade through a maze of devices, programs, or cyclic storage facilities while utilizing the cloud to retrieve them. Amazon SimpleDB automatically and geo-needlessly replicates customers’ data across many servers to provide high availability [34]. With Amazon SimpleDB, a single on-premises database is not a weak link, and your data is always available for you to access. You may store all of your data in a single location and access it from any device using online management tools.
All of the rest is handled by Amazon Web Services, saving you the time and effort to manage your data. • There is no management in place. Setting it and forgetting it demonstrates that you are not devoting sufficient time to keeping an information database to store and handle data logs, which is detrimental to your business. The amount of redundant storage has been reduced. (RRS) By holding non-basic, repeating data at lower excess levels than Amazon S3’s standard stockpile, Amazon S3 customers may cut their expenditures. Amazon S3 provides the capacity option known as RRS. When distributing or sharing data that has been carefully preserved elsewhere, it is a convenient and accessible choice. It can also store thumbnails, transcoded videos, and other managed information rapidly duplicated. By employing the RRS option, you may store far more data in a smaller amount of space than a conventional circular drive, and it does not need you to repeat the same data as many times as Amazon S3 does [35] [36]. A glacier in the Amazon basin With Amazon S3, you may use the incredibly low-cost storage management provided by Amazon Glacier as a capacity option. Alternatively, if you simply need to access a piece of data now and again, Amazon’s Glacier service is an excellent choice since it costs only $0.01 per gigabyte per month. Financial and medical records, basic genetic succession information, and long-term data set reinforcements are all included in the models’ data set reinforcement schemes[]. This section also contains information that should be kept on file for administrative consistency. The administration is in charge of the board’s artificial intelligence methods. Several speculative ideas on how to enhance the learning process are provided by machine learning hypotheses, while in the long term, these proposals are beneficial.
Several previous questions sought to determine if machine learning algorithms might be used to forecast how application assets will be utilized. An application’s assets, such as the amount of CPU, memory, plate, and organization required by the program and the time range in which the assets are active, maybe forecasted using directed artificial intelligence [37]. The framework’s understanding of a notion must be based on reliable facts from previous program runs. As a consequence of prior experiences, new information is seen as such. Artificial neural networks (ANNs), support vector machines (SVMs), and time-series approaches are used in asset utilization and utilization learning and forecasting, among other applications.
Profile-Driven storage makes it feasible to set expenditures for new equipment, media, and people charges limited to a single monthly administration fee using a profile-driven storage architecture. Nevertheless, although traditional procedures may be quite effective, they need a significant investment of time and money [38]. Safaricom’s Cloud Backup Solution is designed to avoid these problems based on the Internet. Safaricom Cloud Backup may be set up in a matter of minutes by downloading the application and following the on-screen instructions [39]. To get started, click here. It is no longer necessary to search for the correct tape or wait for IT specialists to retrieve lost data. The transmission of reinforcement data from the customer’s website to Safaricom’s data storage will be accomplished via the use of an SSL-encrypted Internet connection [40]. A disk-to-disk information backup and recovery option are offered to maximize network efficiency. There is a single point of contact for administration. In addition, there is the possibility of convenience and policy-based control. Having a reliable and effective platform for wholly automatic and secure information backup and recovery may be beneficial to servers, data sets, work locations, and PC devices, among other things. The reinforcement cycle is more secure since it does not include the possibility of human error. It is possible to change the default value for the backup plate limit with the assistance of two-factor authentication and backup plate constraints, but this is not recommended [41].
Research Methodology
In this study, artificial intelligence algorithms were examined to determine which one would be the most effective for learning capacity asset utilization plans for cloud clients and anticipating future asset usage designs. The scientist in this example opted to concentrate on administered education since the information gathered may be utilized as a foundation for learning and predicting using artificial intelligence technologies.
To be termed independent, the characteristics of the dependent variable must be observable and predicted by other variables. The most important indicators in this study were the consistency of asset usage and the overall asset utilization after half a year. The following is a partial list of things that no one else has the power to change: Indicator variables or free factors may be used to forecast the value of an award or target factor. Although asset utilization was a dependent variable in this research, the demand for assets from customers and the total number of customers in the company also had an independent component.
Data collection
A phone call to the appropriate persons gave the Safaricom frameworks engineers the information they needed. Seventy percent of the data gathered by Safaricom Limited was reenacted and reanalyzed utilizing bend fitting techniques [30]. According to real-time statistics provided by Safaricom, people are amassing record amounts of the aforementioned item. This data collection also includes information on asset usage and customer demand. This information was sent to the appropriate business organizations before the event. Safaricom Ltd’s clients were able to request and use scattered storage assets as a result of the information. They were determined to be the most important in the investigation. To gather information for this study, Safaricom cloud computing managers were questioned in person. The data was acquired over a year and a half. The period considered was from the start of 2013 to the end of 2013. There were requests for almost 1,000 terabytes of data. At the commencement of the trial period, all essential data would need to be provided. No restriction exists on the number of datasets that may be produced. Only 30 of the 200 documents examined had genuine information from Safaricom, while the other 170 were created by the researchers.
The first 30 rows include live data, whereas the next 70 rows contain duplicate data. The report’s addendum section contains all of this material. To facilitate comprehension of the calculation approach in the reenactment, a 200-record instructional index is required. The data were generated using Statfit programming, which offered a portion of the data for the evaluation.
The following is a summary of the findings: The primary objective of this postulation was to perform in-depth research of artificial intelligence methodologies for optimizing cloud computing infrastructure as a service capacity allocation (IaaS). As a result of this, cloud computing specialist businesses like Safaricom were able to design their capacity foundations based on this knowledge. An artificial intelligence calculation based on test results and surveys has been offered as SVM (Support Vector Machine). SVM may thereby boost expectations, which can subsequently be utilized to improve cloud administration delivery and eventually to improve everyone’s quality of life. SVM The support vector machine (SVM) learning method provides the most trustworthy forecast when it comes to using artificial intelligence (AI) to estimate cloud system resource usage. This element’s evolution is predicted to continue. Only the DTREG model could predict the future; other models, such as WEKA and Hadoop, were recommended to use. We advocate developing dynamic models for cloud asset consumption in response to changing customer needs. Research on how AI systems may be implemented on cloud computing platforms like PaaS and SaaS, according to experts, will need to continue. Clients may be adequately encouraged, and the cloud service provider may be better prepared based on these estimates.
Using artificial intelligence (AI) methodologies, researchers determined the most accurate prediction device for usage in a cloud computing system. Direct relapse, Support Vector Machines (SVMs), and artificial neural networks (ANNs) were among the artificial intelligence (AI) technologies employed in the research. For cloud customer administration, testing was conducted to determine whether or not the administrations advised were used. The DTREG program analyzed the data, and as a consequence, two important papers were generated: information for preparation and knowledge for approval, respectively. One section had assets that had been discussed, while the other contained assets put to practical use [32]. Using DTREG software, the preparation and testing data was input, and the classifier was trained using the training data before being utilized to execute a grouping operation on the test data, as previously explained. As a result, DTREG would modify the data in line with the chosen model, and the research would then report the results.
Data Exploration and Interpretation
Precision information processing with predictive capabilities Collection of the data on the accuracy of the forecast made The exams were designed to extract information regarding the expectation results from the different AI procedures in the form of charts and tables analyzing the genuine stanzas and expected outcomes, the coefficient of difference between the actual and anticipated sections, and the various proportions of exactness for the different AI approaches, including mean outright rate blunder (MAPE), the connection between the actual and anticipated components, and mean square error. The research included the following: (MSE). All of the tests were carried out with the help of DTREG programming, and the findings were classified and displayed in the form of Microsoft Excel graphs. We used charts to compare the actual data provided to the model with the expected outcomes created as a consequence of the model.
Procedures for comparing machine learning outcomes
The support vector machine (SVM), direct relapse, and fake neural organizations were used to examine artificial intelligence calculations (ANN). The experiments were carried out on DTREG while adjusting the boundary conditions to discuss how the results differed. A precision test was conducted, and an artificial intelligence calculation results as part of the trials. The coefficients of variation (CV) in the learning calculations, the mean absolute rate error (MAPE), the relationship between actual and predicted components, and the mean square error were all detected throughout the experiment (MSE). For the sake of quantifying the calculations’ display, the following metrics will be reviewed as part of the research study process. The mean absolute rate error (MAPE), the coefficient of variation (CV), the root mean square error (RMSE), and the correlation between actual and projected data are all included in this set of measures.
Results and Analysis
Here is a description of the audit and research of the results acquired after directing the different correlations of the AI calculations using the DTREG equipment, which is covered in-depth in the following section: Additionally, it has a plethora of findings that were utilized to assess the precision of the numerous calculations that were performed.
Data sets gathered
The informative index that was constructed comprised of 30 Safaricom records that were used to replicate another 200 datasets as the preparation dataset, which was then utilized to create the informative index. It was necessary to introduce the preparation information in the Microsoft.csv format, which comprises 200 data pieces. In addition to the capacity measure given, the capacity measure utilized and the number of clients inside a particular company were all restricted by the system. In the experiments, this information was used as the basis for decision-making. A data collection structured logically, Safaricom data was utilized to produce new data via recreation, and the resulting datasets were integrated into the index portion of this collection. Figure 1 shows that requests for abstinence are made for more than a half year. Using this chart, you can see that client usage of the specified asset is not stale and has been consistently increasing over time.
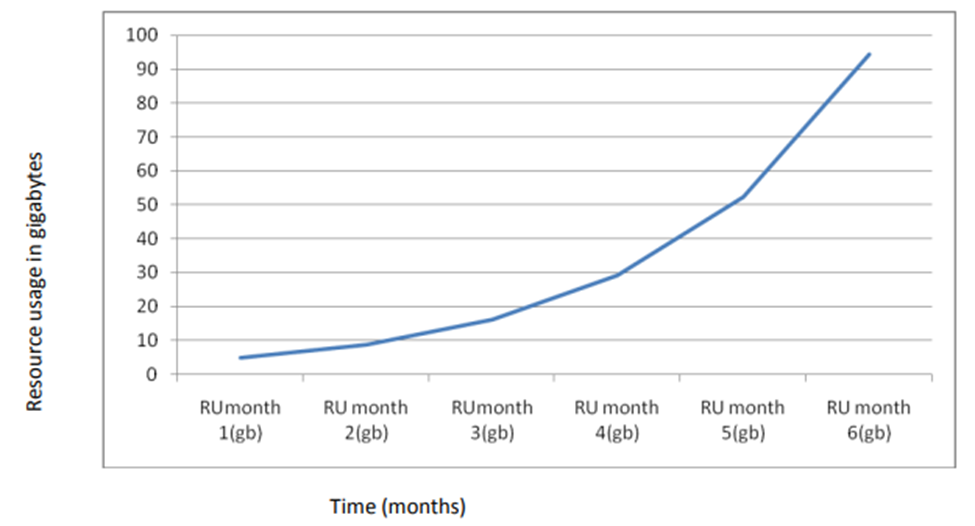
Figure 1: Usage against resources
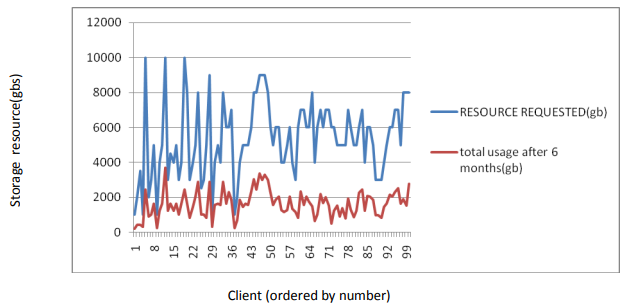
Figure 2: The resource against usage
Accuracy in predicting asset utilization
In this case, the output of the machine learning instrument was created in the form of product reports. Figure 2 illustrates the resource against usage. Exactness proportions for different learning models are shown in Table 1 below.
| Machine learning model | Variance | Coefficient of variance | Root mean square error | Mean percentage error | Mean square error | Correlation between predicted and actual values |
| Linear regression | 559508 | 0.28 | 456 | 28.9 | 208506 | 0.80 |
| SVM | 559508 | 0.26 | 420 | 25.9 | 176824 | 0.84 |
| ANN | 559508 | 0.25 | 414 | 27.8 | 171407 | 0.76 |
Table 1: Presentation of cloud storage strategy
Calculations
Comparison of the accuracy of the expectations obtained by the different calculations
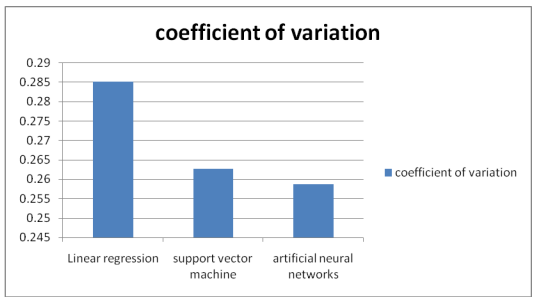
Figure 3: Variation coefficient

Figure 4: Mean square root error
In general, the lower the coefficient of variation, the closer the residuals are to the experiment’s projected outcome. This demonstrates that the model is well-suited to the scenario. The findings of this example study indicate that the ANN model provides the best fit, followed by the SVM model, because of their lower coefficients of variation.
At least two factual models may be evaluated in terms of their MSEs, which quantify their ability to adequately explain a given arrangement of perceptions. By and large, the unprejudiced model with the smallest MSE is judged to be the most successful at describing the disparity in opinions. According to our experiment results and dataset, ANN and SVM had the most modest characteristics and hence would be the most suitable calculating choices to examine.
According to the data from our experiments, the lower the mean outright rate blunder (MAPE), the better when examining this parameter. When this parameter was examined, SVM had the lowest mean outright rate mistake.
As seen in the graph, SVM displayed the highest degree of correlation between the actual and predicted values. When it comes to an expectation model, a greater correlation value is desired. SVM is the most effective approach for identifying correlations based on the outcomes of trials in artificial intelligence.
The expert then utilized the mean of the aforementioned characteristics to determine which artificial intelligence calculation should be applied in this specific instance of cloud storage asset utilization. Each of the three estimations is discussed in detail. Specifically, the fluctuation of the coefficients, the root mean square error, the mean outright deviation, and the correlation between actual and projected data.
This case demonstrates that a support vector machine (SVM) is the most effective artificial intelligence approach and that it can be used to predict customer stockpiling asset utilization designs for a cloud computing Iaa instance, based on the results of the scientist’s experiments with various measurements, including mean absolute percent error (MAPE), root means square error (RMSE), and coefficient of variation. This kind of analysis may be used to investigate instances of capacity asset use, and the resulting pattern can be utilized to advise customers on future stockpile asset needs. Cloud computing providers may also benefit from using use cases to prepare for their assets since they may get expected customers’ cumulative asset needs and more accurately forecast their future support functions. Constraints and roadblocks When it comes to obtaining real-world data from a cloud service provider, the scientist is well aware of the obstacles that must be overcome. This explanation was based on evaluations, and the analyst believed that in the future, client asset solicitation and usage designs would remain broadly similar. Due to time constraints, the analyst was only able to do a DTREG study; nevertheless, the expert suggests that additional devices might be used to broaden the scope of the investigation.
Conclusion and Future Recommendations
The following is a summary of the findings: The primary objective of this postulation was to perform in-depth research of artificial intelligence methodologies for optimizing cloud computing infrastructure as a service capacity allocation (IaaS). As a result of this, cloud computing specialist businesses like Safaricom were able to design their capacity foundations based on this knowledge. An artificial intelligence calculation based on test results and surveys has been offered as SVM (Support Vector Machine). SVM may thereby boost expectations, which can subsequently be utilized to improve cloud administration delivery and eventually to improve everyone’s quality of life. SVM The support vector machine (SVM) learning method provides the most trustworthy forecast when it comes to using artificial intelligence (AI) to estimate cloud system resource usage. This element’s evolution is predicted to continue. Only the DTREG model could predict the future; other models, such as WEKA and Hadoop, were recommended to use. We advocate developing dynamic models for cloud asset consumption in response to changing customer needs. Research on how AI systems may be implemented on cloud computing platforms like PaaS and SaaS, according to experts, will need to continue. Clients may be adequately encouraged, and the cloud service provider may be better prepared based on these estimates.
References
[1] Matsunaga, Andréa, and José AB Fortes. “On the use of machine learning to predict the time and resources consumed by applications.” 2010 10th IEEE/ACM International Conference on Cluster, Cloud and Grid Computing. IEEE, 2010.
[2] Antoine Bordes, Léon Bottou, Patrick Gallinari, and JasonWeston.Solving MultiClass Support Vector Machines with LaRank In Zoubin Ghahramani, editor, Proceedings of the 24th International Machine Learning Conference, pages 89–96, Corvallis, Oregon, 2007. OmniPress.URL http://leon.bottou.org/papers/bordes-2007.
[3] Corinna Cortes and Vladimir Vapnik. Support vector networks. In Machine Learning, pages 273–297, 1995.
[4] Daniel Nurmi, Rich Wolski, Chris Grzegorczyk, GrazianoObertelli, Sunil Soman, LamiaYouseff, DmitriiZagorodnov. “The Eucalyptus Open-source Cloud-computing System”.In Proceedings of the IEEE/ACM International Symposium on Cluster Computing and the Grid, 2009. IEEE Press.
[5] Dustin Amrhein, Scott Quint. Cloud computing for the enterprise – Understanding cloud computing and related technologies: Part 1: Capturing the cloud. http://www.ibm.com/developerworks/websphere/techjournal/0904_amrhein/0904_amrhein.html, 2009.
[6] Gihon Jung, Kwang Mong Sim, Location-Aware Dynamic Resource Allocation Model for Cloud Computing Environment, in Proceedings of International Conference on Information and Computer Applications, Dubai, 2011. 74
[7] Hsuan-tien lin, Ling Li .” Support vector Machine for Infinite Ensemble learning”. Journal of machine learning 9 2008 pg 286-312
[8] Ian H. Witten; Eibe Frank, Mark A. Hall “Data Mining: Practical machine learning tools and techniques, 3rd Edition”. Morgan Kaufmann, San Francisco. Retrieved 2011-01-19.
[9] Kotsiantis S.B, Supervised Machine Learning: A Review of Classification Techniques. Informatica31:249–268 2007
[10] Kothari, Chakravanti Rajagopalachari. Research methodology: Methods and techniques. New Age International, 2004.
[11] L. Jiang, H. Zhang, Z. Cai, and J. Su. Learning Tree Augmented Naive Bayes for Ranking. Proceedings of the 10th International Conference on Database Systems for Advanced Applications, 2005.
[12] Addero, Edgar Otieno. Machine learning techniques for optimizing the provision of storage resources in cloud computing infrastructure as a service (ideas): a comparative study. Diss. 2014.
[13] Mitchell, Tom M., et al. “Learning to decode cognitive states from brain images.” Machine learning 57.1 2004: 145-175.
[14] V.Vinothina, Dr.R.Sridaran, Padmavathi Ganapath A Survey on Resource Allocation Strategies in Cloud Computing,(IJACSA) International Journal of Advanced Computer Science and Applications, Vol. 3, No.6, 2012
[15] Yogesh Singh, Pradeep Kumar Bhatia & Omprakash Sangwan A review of studies on machine learning techniques International Journal of Computer Science and Security, Volume 1: Issue (1), 2017
[16] Goodfellow, Ian, Yoshua Bengio, and Aaron Courville. “Machine learning basics.” Deep learning 1.7 2016: 98-164.
[17] Jordan, Michael I., and Tom M. Mitchell. “Machine learning: Trends, perspectives, and prospects.” Science 349.6245 (2015): 255-260.
[18] Zhang, Xian-Da. “Machine learning.” A Matrix Algebra Approach to Artificial Intelligence. Springer, Singapore, 2020. 223-440.
[19] Shavlik, Jude W., Thomas Dietterich, and Thomas Glen Dietterich, eds. Readings in machine learning. Morgan Kaufmann, 2016
[20] El Naqa, Issam, and Martin J. Murphy. “What is machine learning?.” machine learning in radiation oncology. Springer, Cham, 2015. 3-11.
[21] Mohri, Mehryar, Afshin Rostamizadeh, and Ameet Talwalkar. Foundations of machine learning. MIT Press, 2018.
[22] Singh, Amanpreet, Narina Thakur, and Aakanksha Sharma. “A review of supervised machine learning algorithms.” 2016 3rd International Conference on Computing for Sustainable Global Development (INDIACom). Ieee, 2016.
[23] Kotsiantis, Sotiris B., I. Zaharakis, and P. Pintelas. “Supervised machine learning: A review of classification techniques.” Emerging artificial intelligence applications in computer engineering 160.1 2007: 3-24.
[24] Jiang, Tammy, Jaimie L. Gradus, and Anthony J. Rosellini. “Supervised machine learning: a brief primer.” Behavior Therapy 51.5 2020: 675-687.
[25] Schrider, Daniel R., and Andrew D. Kern. “Supervised machine learning for population genetics: a new paradigm.” Trends in Genetics 34.4 2018: 301-312.
[26] Huo, Haoyan, et al. “Semi-supervised machine-learning classification of materials synthesis procedures.” NJ Computational Materials 5.1 2019: 1-7.
[27] Lynch, Chip M., et al. “Prediction of lung cancer patient survival via supervised machine learning classification techniques.” International journal of medical informatics 108, 2017: 1-8.
[28] Muhammad, Iqbal, and Zhu Yan. “SUPERVISED MACHINE LEARNING APPROACHES A SURVEY.” ICTACT Journal on Soft Computing 5.3 2015.
[29] Nasteski, Vladimir. “An overview of the supervised machine learning methods.” Horizons. b 4 2017: 51-62.
[30] Bhamare, Deval, et al. “Feasibility of supervised machine learning for cloud security.” 2016 International Conference on Information Science and Security (ICISS). IEEE, 2016.
[31] Khan, Muhammad Adnan, et al. “Intelligent cloud-based heart disease prediction system empowered with supervised machine learning.” 2020.
[32] Teluguntla, Pardhasaradhi, et al. “A 30-m Landsat-derived cropland extent product of Australia and China using random forest machine learning algorithm on Google Earth Engine cloud computing platform.” ISPRS Journal of Photogrammetry and Remote Sensing 144 (2018): 325-340.
[33] Er-Raji, Naoufal, et al. “Supervised Machine Learning Algorithms for Priority Task Classification in the Cloud Computing Environment.” IJCSNS Int. J. Comput. Sci. Netw. Secure 18.11 (2018): 176-181.
[34] Wang, Jun-Bo, et al. “A machine learning framework for resource allocation assisted by cloud computing.” IEEE Network 32.2 2018: 144-151.
[35] Nawrocki, Piotr, and Bartlomiej Sniezynski. “Adaptive service management in mobile cloud computing using supervised and reinforcement learning.” Journal of Network and Systems Management 26.1 (2018): 1-22.
[36] Bhamare, Deval, et al. “Feasibility of supervised machine learning for cloud security.” 2016 International Conference on Information Science and Security (ICISS). IEEE, 2016.
[37] Mohanty, Sachi Nandan, et al. “Next Generation Cloud Security: State of the Art Machine Learning Model.” Cloud Security: Techniques and Applications. 2021: 125.
[38] Salman, Tara, et al. “Machine learning for anomaly detection and categorization in multi-cloud environments.” 2017 IEEE 4th International Conference on Cyber Security and Cloud Computing (CSCloud). IEEE, 2017.
[39] Abdelaziz, Ahmed, et al. “A machine learning model for improving healthcare services on the cloud computing environment.” Measurement 119 2018: 117-128.
[40] Li, Mingwei, et al. “Distributed machine learning load balancing strategy in cloud computing services.” Wireless Networks 2019: 1-17.
[41] Inani, Anunaya, Chakradhar Verma, and Suvrat Jain. “A machine learning algorithm TSF k-Nn based on automated data classification for securing mobile cloud computing model.” 2019 IEEE 4th International Conference on Computer and Communication Systems (ICCCS). IEEE, 2019.
 write
write