Abstract
This study compares the accuracy with which different machine-learning models can predict solar radiation. The research uses Meteorological data from the National Renewable Energy Laboratory (NREL) to study GHI clear-sky GHI types of cloud wind speed, relative humidity, temperature, and pressure. The study uses exploratory data analysis to explore relationships among those factors. The Random Forest is a stable model that can be adapted to New York’s constantly changing environment and has high accuracy. Several evaluation metrics, such as Root Mean Squared Error, R-squared, and Mean Absolute Error, indicate that Random Forest outperforms both the LSTM model and Transfer Learning framework. These results underline that machine learning can help improve solar radiation predictions’ accuracy when properly developing sustainable energy policies for cities.
Keywords: solar energy, machine learning, prediction models, New York City. Random Forest. Transfer Learning Long Short-Term Memory (LSTM), meteorological data, environmental sustainability, and energy planning in New York.
Introduction
Known for its environmentally friendly properties, solar energy is essential in the quest for alternative and clean energy sources. On the one hand, there is increasing concern over environmental protection, but on the other, new technical breakthroughs are being made. Moreover, as steam heat takes up a relatively large place in coupled multi-source heating systems–one of our significant problems related to environmental pollution today concerns traditional technologies applied through appropriate means of retrofitting so that they can remain part and parcel with modern technology for years to come. However, solar heat is, of its very nature, a rarity. This exceptional quality makes it challenging to pre-ordain these variations in extremes. Geography and climate are auxiliary conditions that provide chance or irregularity in the order of things. Because accurate solar radiation prediction depends on several environmental factors, the heating system cannot be controlled efficiently.
The data used in the study are GHI meteorological data for New York State obtained at NREL (2019-2021). Prediction of GHI is affected by clear-sky GHI, type and extent of cloud cover, wind speed, relative humidity, temperature, and atmospheric pressure. EDA pictures have been used to explore these relationships.
Historically, solar radiation prediction employed various approaches:
- Numerical Weather Prediction and Pictures of Physical Models.
- Classic/traditional statistical models such as multiple linear regressions and the ARMA model mathematically generate relationships.
- Traditional machine learning methods like SVM and MLP seek to increase prediction accuracy.
- RNN or GRU are two deep learning algorithms that are particularly good at complex nonlinear sequences.
Such accurate forecasts of solar irradiance are vital, all the more now that large-scale PV installations have been integrated on a much larger scale and suffer from disruptive variability (Voyant et al., 2017). Solar energy prediction machine learning models are essential to random Forest, LSTM, and transfer learning. For example, location and Random Forest are very accurate, but LSTM holds data better. It is a method of handling scarce data and recognizing seasons and trends.
Review of the Literature
Regarding prediction statistics, methods include traditional statistical approaches and more modern machine learning techniques. This review promotes a dialogue on breakthroughs and analysis in this area. Aria et al. (2021) investigated frameworks for RF, an ensemble learning method applied in solar radiation forecasting. Their research focused on understanding the readability of RF models and how changes in input parameters affect what results you get for radiation prediction. In that vein, Manju Sandeep (2019) looked at using an RNN LSTM model in large-scale multi-machine power systems with particular attention to fault detection.
Ibarra and Reinhart (2010) analyzed six methods of irradiation distribution, where accurate solar availability forecasts are crucial factors. In a review of the machine learning techniques currently used in solar radiation forecasting, Voyant et al. (2017) identified their pros and cons. Manju and Sandip (2019) compared predictions of solar radiation across India with accurate data from satellites versus surface observations. The estimation of global solar radiation has been studied by Güher et al. (2020) using machine learning algorithms. Later, Ali et al. (2023) optimized ANNs for radiation forecasting and compared their performance with traditional methods.
Examples showed how Al Sulttani et al. (2021) used general ensemble methods to forecast changes to forecast changes. Ali et al. (2020) developed a modeling method based on ensemble methods to predict rainfall.
Methods
LSTM
Moreover, transfer learning is training a model for the source task and increasing its capacity to do the target task with transferred knowledge. For example, solar irradiance is estimated for New York City and surrounding areas, which have a climate similar to that of New York. Finally, the target task is to predict absolute solar irradiation amounts in the city. First, by reusing pre-trained models from other fields or building on top of them; secondly, by retaining knowledge learned in similar research work. New York City’s weather patterns will strongly impact some parts of the model, including feature extraction, fine-tuning, and domain adaptation. These will help increase data efficiency generalization and reduce training time. The problems are finding a source task, understanding the differences between domains, and achieving this adaptation.
LSTM is an excellent recurrent neural network for forecasting solar radiation. It is well suited for handling temporal dependencies and is an excellent model to predict solar radiation. Temporal change extraction, meteorological condition adaptation, and nonlinearity handling for New York City are all parts of the application of LSTM to irradiation data that is neither classical linear nor constant. In addition, there is automatic picking up or use from existing situations on hand with no need to extract features alone. Only by such comparison studies using methods from Random Forest to Transfer learning will we be able to determine the strong and weak points of different sunshine prediction modes in NYC.
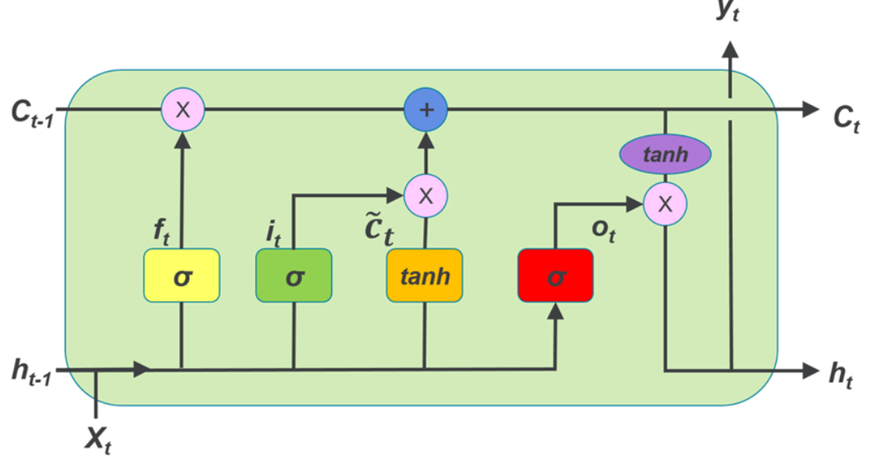
Figure 1: LSTM
Transfer learning
The idea that learning is transitional means we teach a model first on the source task, so its performance about another target task can be optimized by wisdom gained. The first source task might be the solar irradiance prediction in areas with similar climates, such as New York City. Secondary target tasks may be forecasts of solar irradiance in New York. We aim to improve the quality of machine learning models for solar radiation modeling in NYC through transfer learning by either using a pre-trained model or getting a specific task from another area. Examples are feature extraction, fine-tuning, and domain adaptation, essential use domains. Thus, this model employs these techniques to bring New York City’s weather patterns into the whole. Therefore, there is a data economy because it saves generalization and training time. However, these are precisely the problems of choosing an appropriate source task job and arranging domain transfers, which may need to be modified by redesigning transferred learning procedures.
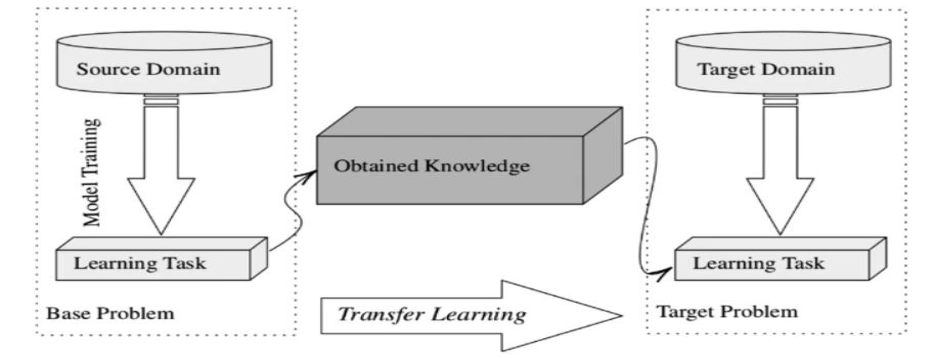
Figure 2: Transfer learning
Random Forest
A powerful ensemble method, Random Forest, can accurately forecast the level of solar radiation in New York City. It has many decision trees and can adequately capture the intricate correlations between important variables like clear-sky radiation, cloud coverage, and background atmospheric parameters. Solar irradiance can be approached as a return to equilibrium, and the power law that it satisfies reflects its dynamic structure. This means one uses nonlinear patterns and highly interconnected components in modeling solar energy–precisely what random forest is extremely good at doing. Prediction of such phenomena has always been important. Thanks to Random Forest’s combined approach, it never over-runs, and its accuracy is high; you can also see why a particular feature is essential or what factors influence solar radiation. Moreover, one of the most critical tools for exploiting New York City’s solar energy resources, Random Forest, is also flexible in adjusting to different datasets.
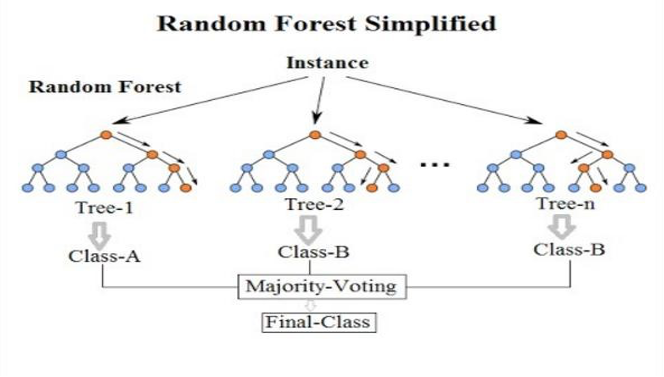
Figure 3: Random Forest Process Source: TIBCO
Performance Evaluation
Several statistical indicators indicated the reliability of predicted solar radiation values, such as R², MRS (as Mean et al.), and RMSE (Root Mean Squared Error). RMSE is the difference between modeled values and observation data sets. Therefore, the score becomes one of several ways to judge how well a given model performs, particularly predictive modeling. MAE (mean absolute error) is the difference between actual and estimated values based on a model. This may also serve as an indicator of the predictive power of models in evaluation. R squared (R2) measures the relative discrepancy between expected and actual variances. R2 ranges from zero to one (0-1). However, the minimum limit is zero. Thus, this model cannot explain the variance registered in the dependent variable. Its maximum value signifies that it thoroughly explains the variance recorded. R2 is more significant, meaning the fit of the fitted model against the observed data is better.
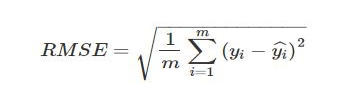
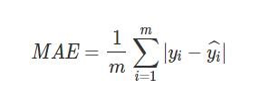
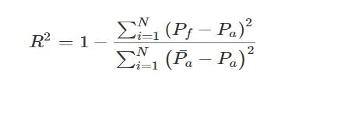
Data collection and preparation
Information from NREL (National Renewable Energy Laboratory) database is open to the public. The study looked at data about patterns of solar irradiance in New York City for 2019-2021. New York has no transparent dry season because of its humid subtropical climate. In summer, the temperature often reaches over 71 degrees Fahrenheit. Winter temperatures, however, can reach about 18 degrees Celsius. In addition to daylight hours, the city’s year-round sunshine must be considered when appraising solar energy forecasting. The research concentrated on three principal solar radiation measures: Global Horizontal Irradiance (GHI), direct irradiance, and the spread of cone angles for diffuse irradiances incident upon a flat surface.
The GHI–or the solar heat flux at a particular location- affects how well PV panels perform. Also considered in the research is direct normal irradiance (DNI), which comes from direct sunlight, and diffuse horizontal irradiance (DHI), which comprises horizontal irradiation at ground level of dispersed solar radiation. The sum of DHI and DNI is our GHI, a pivotal factor in this investigation into solar radiation over New York City.
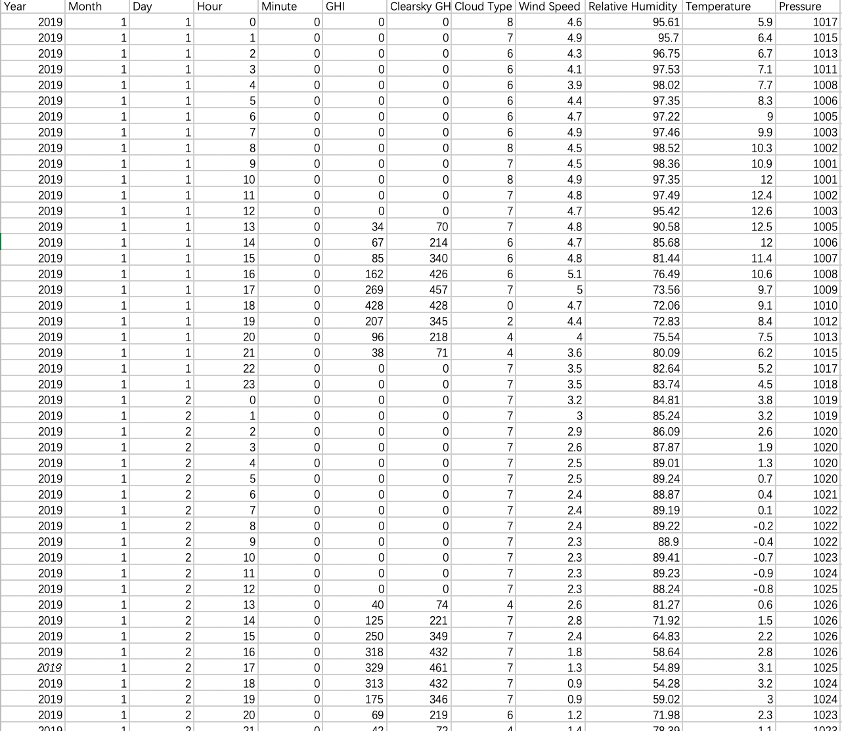
Table 1: New York Soler Sheet
New York’s primary energy is solar radiation, which means many kinds of sunlight. Powering solar systems and defining local atmospheric phenomena, photons compose the visible light we see along with ultraviolet (UV) and infrared. The amount of solar radiation received by the earth’s surface is determined by atmospheric conditions, varying distances from and inclination toward the sun. This work predicts GHI all over New York City based on clear sky GHI, cloud type, wind speed, relative humidity, temperature, and air pressure. We investigated how these factors affect solar Prediction and energy in the city using EDA images, so we got an exact prediction.
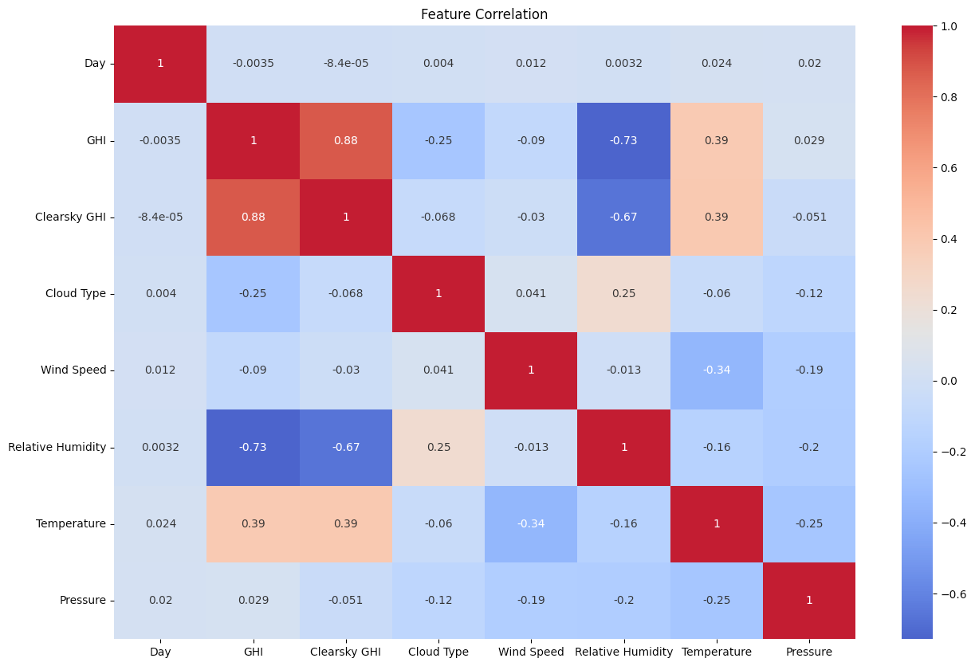
Table 2: GHI Feature Correlation
EDA is a procedure that includes data analysis and summary to find hidden relationships. In New York City, it is often called Exploratory DA for the ease of use alone. Finding trends, patterns, and outliers that would be hard to spot just by looking at the data is vital in this critical step of the data science workflow. That is what this case about the New York City dataset is all about. Furthermore, a clear sky GHI’s coefficient concerning GHI is very high at 0.89, revealing their relationship. Another correlation between temperature and GHI shows their existing relationship is 0.62. However, the relationship between relative humidity and global horizontal irradiance (GHI) is negative. R = –0.60.
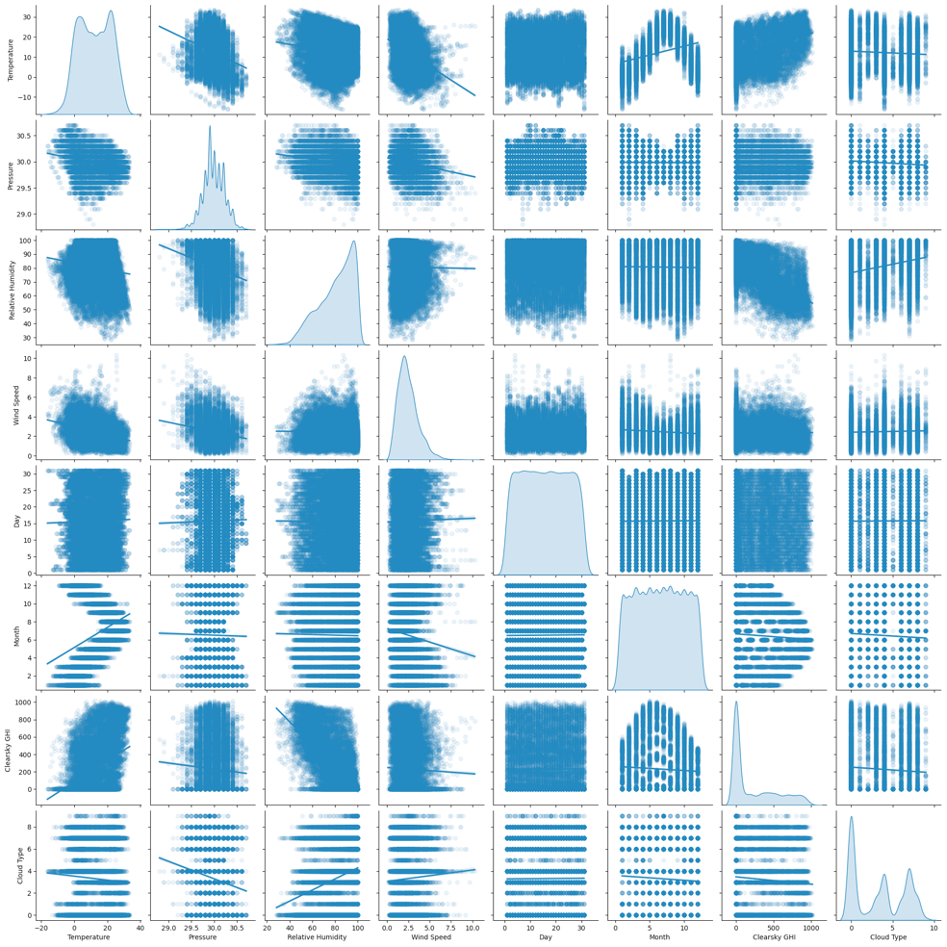
Figure 4: Relevance
Results
The training involved the previously established weather parameters, including temperature, precipitation, wind speed, and cloudiness, which served as references for better fitting the models used. Figure 6 compares predicted and actual cases for three models: LSTM, TL, and RF for GHI. For correct assessment, the analysis cuts off the year’s four seasons. It is important to note that Figure 5 shows that Random Forest follows the actual situation closely. Specifically, Random Forest shows a firmer fit, partially due to the lowest and most minor fluctuating average cloudiness, rainfall, and sunshine hours throughout the year in New York City, particularly in summer.
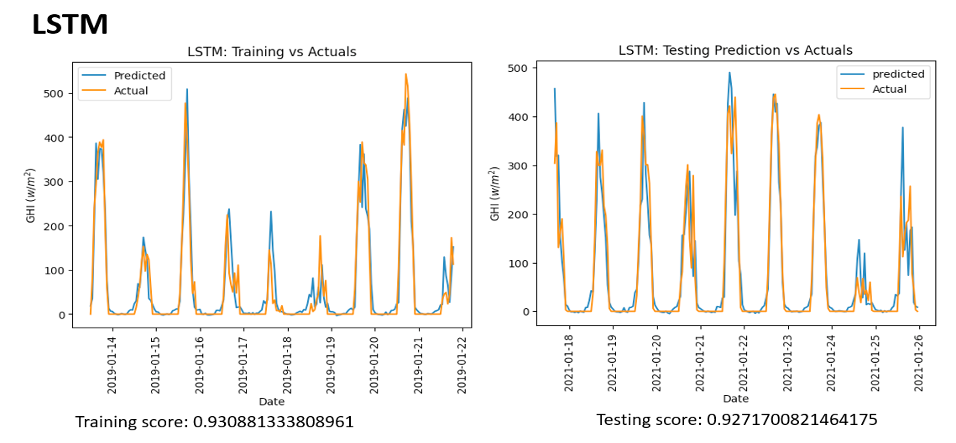
Figure 5: LSTM
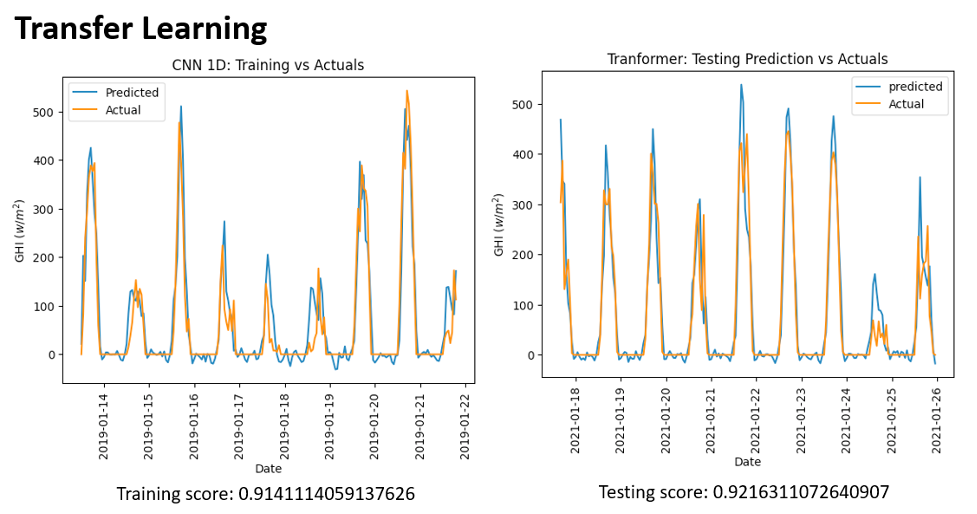
Figure 6: Transfer Learning
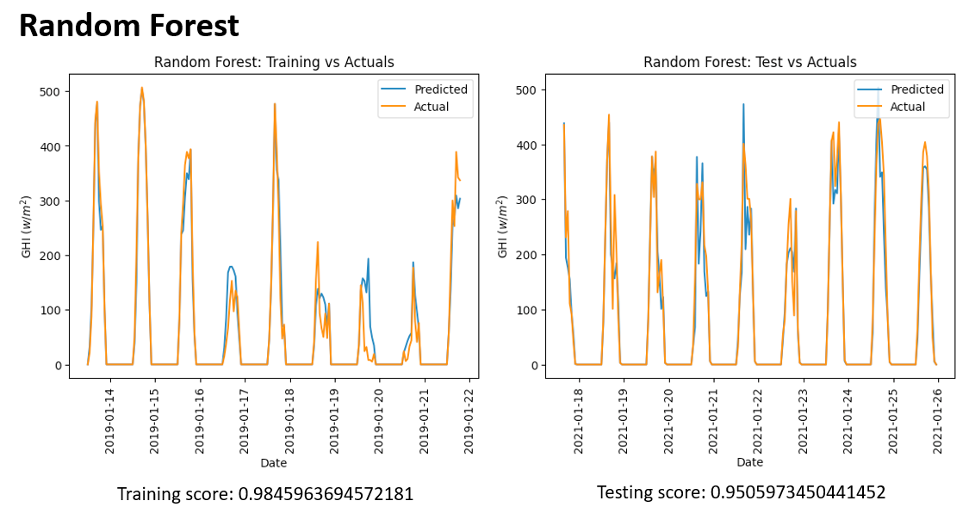
Figure 7: Random Forest
In terms of forecasting solar radiation for New York City, a key indicator is the R-squared statistic, which measures goodness of fit in linear regression; it indicates to what extent variation in dependent variables can be explained by independent variables–R £ squared. Thus, it provides some sense as to how well an explanatory model has performed on balance. Table 1 shows that the Random Forest model has an R-squared value closest to one, which suggests a good fit with solar radiation data. The Root Mean Squared Error (RMSE), an effective indicator of model performance and a way to compare different models on the same data, is essential in finding model problems. Likewise, the Mean Absolute Error (MAE) is used when testing how well solar radiation predictions reflect reality and for further improvement of models. It, too, can be tuned to New York’s peculiar climate conditions.
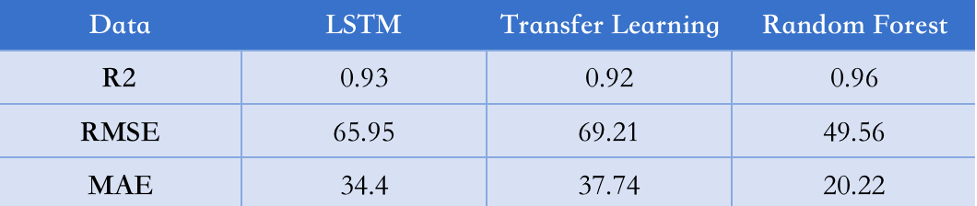
Table 3: R2, RMSE and MAE
So, three more graphs were added to show that Random Forest can be used in this field. In particular, potential applications involving GHI predictions at specific places within New York City are shown here. One of the more critical parameters in machine learning is how strongly the Prediction of a target variable depends on each feature. It, therefore, helps restrict the key features and focus more on variables that will substantially affect GHI. Finally, because this aids interpretation (especially for high-dimensional data in an urban environment), it streamlines the model using fewer features. The many parameters allow us to see the relationships between variables and our objective variable. Furthermore, in New York City, temperature and sunny days are the two most important influences that affect GHI. Moreover, a model verification plot, an almost perfect match between the random forest regression and predictive performance graphics for anomalous NYC conditions, provides more substantiation that you can build a model to forecast GHI.
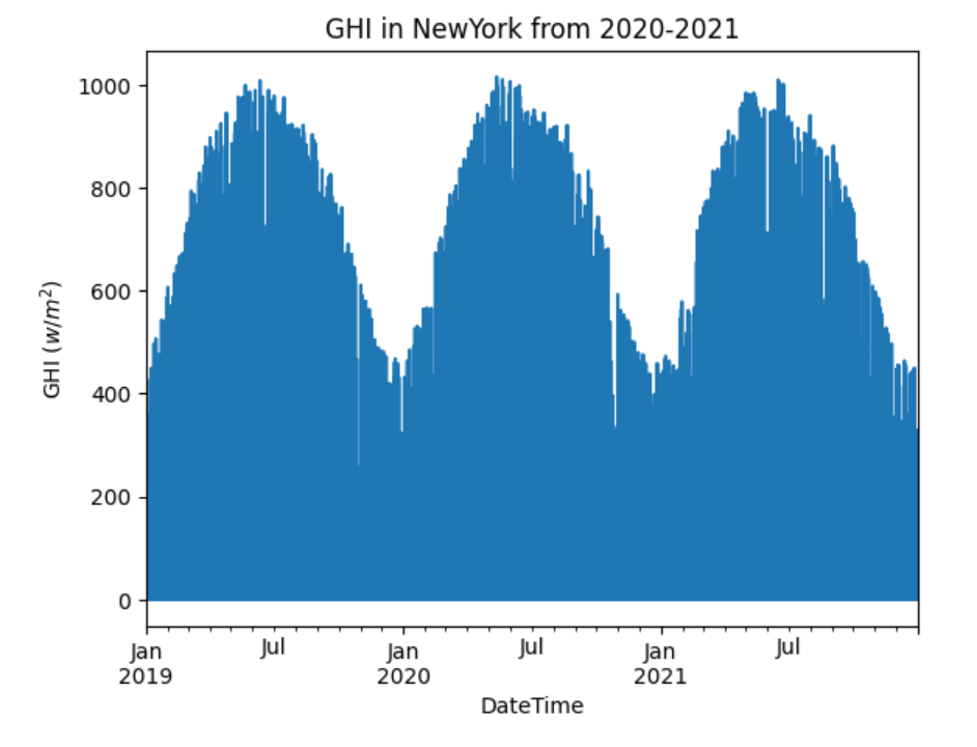
Figure 8: CGI in New York
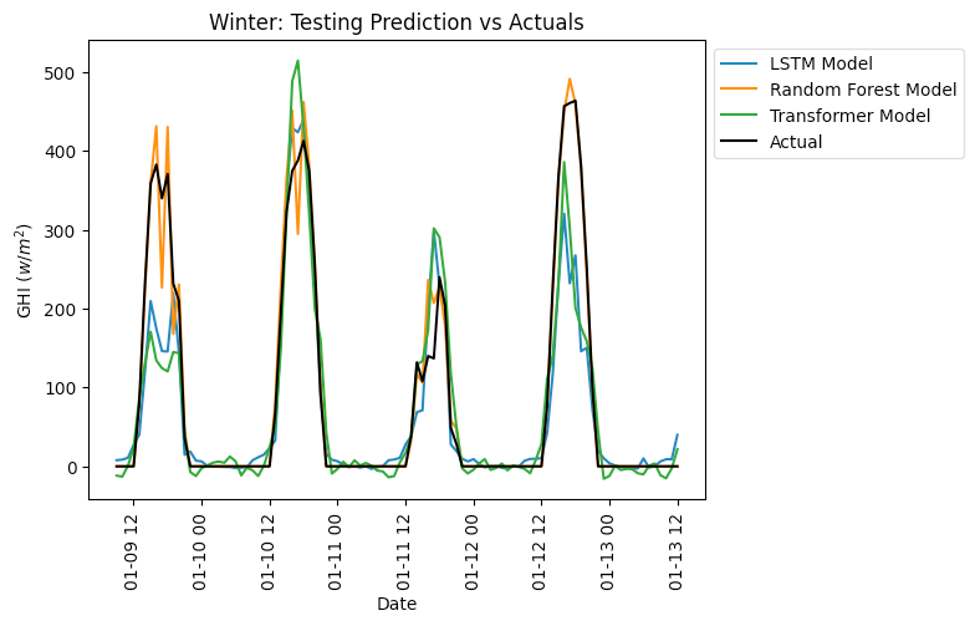
Figure 9: Scenario Winter (12,1,2)
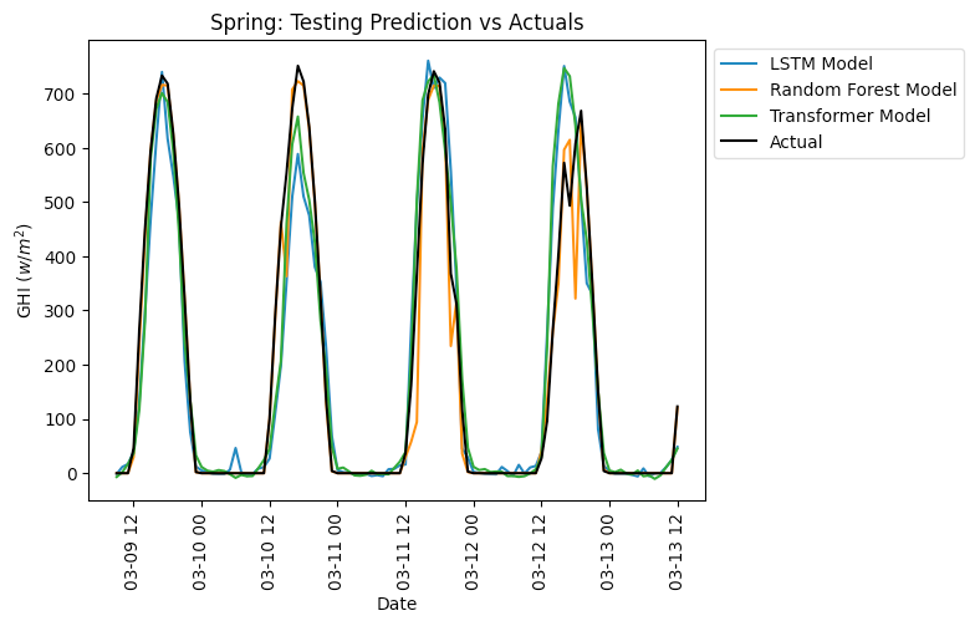
Figure 10: Scenario Spring: (3,4,5)
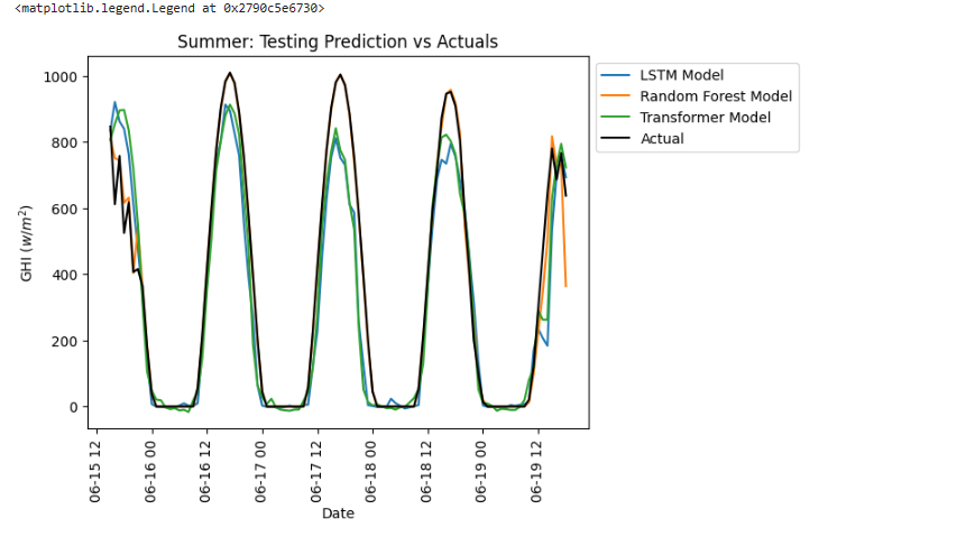
Figure 11: Scenario Summer: (6,7,8)
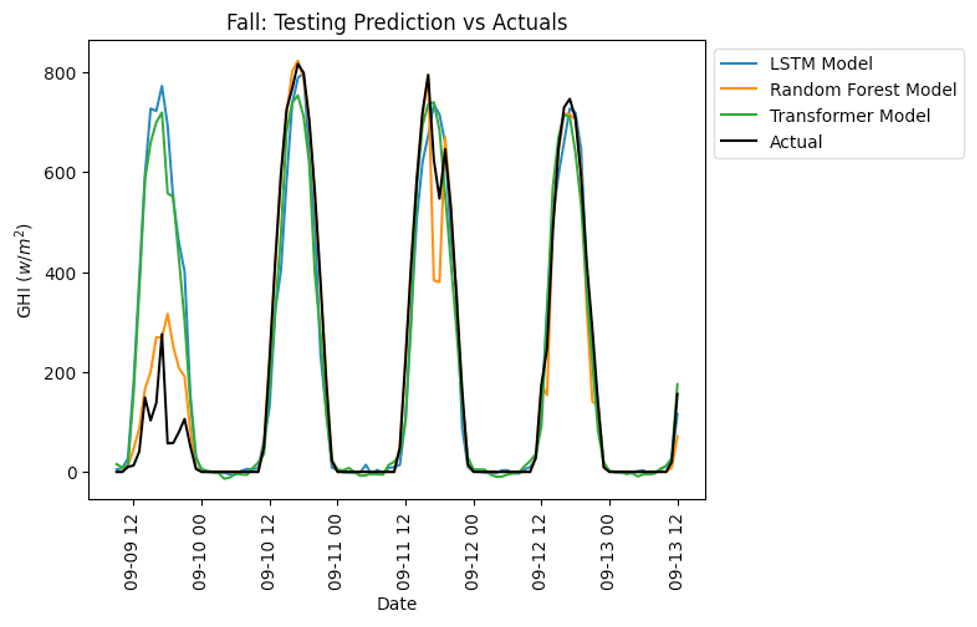
Figure 12: Scenario Fall: (9,10,11)
Solar Radiation Predictions (GHI) adapted for NYC: Three machine learning techniques were used in this study. They include LSTM, transfer learning, and random forest. This is it, namely that Random Forest has better predictive power than other solar radiation forecasting models. Building many decision trees during training is a unique feature of Random Forest, which can also process vast amounts of highly complex data rich in numerous input attributes. At the forecasting stage, it avoids over-fitting when estimating GHI. Random forests are reliable and accurate through ensemble models using many trees. Random forest is important because it can still be accurate even with missing data. It was observed in New York that although the computational complexity is higher, random forest achieves better results than LSTM and transfer learning.
Conclusion
In this instance, three ML algorithms- LSTM, transfer learning method, and random forest- were used to predict GHI in NYC. Here, the Random Forest model proved best at predicting GHI, more accurate than LSTM and Transfer Learning. Several statistical tools were used to measure and evaluate the performance, including R², MAE, and RMSE. The random forest model always came out ahead of all rivals during testing. Secondly, feature importance analysis showed temperature and sunny days as essential factors influencing GHI in NYC’s urban setting. This means that Random Forest can deal with the interdependence among variables and nonlinearity of data, all while being flexible enough for different databases. As such, it also does an excellent job of predicting solar radiation. Accurate forecasting of GHI is also a key factor for PV large-scale solar implementation in order to properly coordinate energy and load. This study provides critical insight into the application of machine learning to solar radiation prediction. It provides valuable guidance on strengthening the reliability of solar energy systems in typical New York City urban environment conditions.
References
Ali, M. A., Elsayed, A., Elkabani, I., Akrami, M., Youssef, M. E., & Hassan, G. E. (2023). Optimizing artificial neural networks for accurate global solar radiation prediction: A performance comparison with conventional methods. Energies, 16(17), 6165. https://doi.org/10.3390/en16176165
Ali, M., Prasad, R., Xiang, Y., & Yaseen, Z. M. (2020). Complete ensemble empirical mode decomposition hybridized with random forest and kernel ridge regression model for monthly rainfall forecasts—Journal of Hydrology, 584, 124647.
Al-Sulttani, A. O., Al-Mukhtar, M., Roomi, A. B., Farooque, A. A., Khedher, K. M., & Yaseen, Z. M. (2021). The proposition of new ensemble data-intelligence models for surface water quality prediction. IEEE Access, p. 9, 108527-108541
Guher, A. B., Tasdemir, S., & Yaniktepe, B. (2020). Effective estimation of hourly global solar radiation using machine learning algorithms. International Journal of Photoenergy, 2020, 1-26. https://doi.org/10.1155/2020/8843620
Ibarra, D., & Reinhart, C. (2011, November). Solar availability: a comparison study of six irradiation distribution methods. In Building Simulation 2011 (Vol. 12, pp. 2627-2634). IBPSA. https://doi.org/10.26868/25222708.2011.1813
Manju, S., & Sandeep, M. (2019). Prediction and performance assessment of global solar radiation in Indian cities: A satellite and surface measured data comparison. Journal of Cleaner Production, 230, 116-128. https://doi.org/10.1016/j.jclepro.2019.05.108
Voyant, C., Notton, G., Kalogirou, S., Nivet, M. L., Paoli, C., Motte, F., & Fouilloy, A. (2017). Machine learning methods for solar radiation forecasting: A review. Renewable energy, 105, 569-582. https://doi.org/10.1016/j.renene.2016.12.095
 write
write