Introduction
In a highly competitive telecommunication sector, fighting customer churn has become an essential concern for service providers. Churning customers to competitors’ behavior is a challenge and must be tackled in the Customer Churn global technological aspects (Yang,2020). To address this challenge effectively, we have developed an innovative e-system that uses sophisticated clustering algorithms like Hierarchical Clustering and K-Means Clustering.
Our unrivaled system has been thoroughly planned to evaluate customers before data thoroughly. On splitting this data, it works efficiently to identify customers into densely discerning sections, each with distinct behavioral character and preferences. This pan enables telecom companies to mine deep insights into customer dynamics, enabling them to customize retention strategies with sophistication. The main objective, therefore, is keeping churn rates, increasing the rate of satisfaction among the customers, and, eventually, increasing telecom providers’ competitive ability in an environment that continues to change every quarter.
System Requirements
Functional Requirements
Data Input
The system can ingest an input dataset containing many such hands of customer data as the customer churn dataset. This dataset has significant features, including a tenure coefficient, total refunds, extra date charges, long-distance charges, and total revenue. These represent the global points we will carry out our clustering analysis, enabling us to subgroup the customers meaningfully.
Clustering
These algorithms allow customer identification in its discrete groups with their behavioral relatedness and identical features. The proposed system equipped with these clustering methods allows the stakeholders to use these strategies to reveal, among other things, how customers make choices and provide insights that are hidden in the data.
Visualization
The data input and interpretation ability is measured within the rest of the functionality of our system, which also offers an intuitive visualization component. With visually rich scatter plots and charts, our system offers a detailed snapshot of how the model assumes that like parts segregate into groups, enabling the users to identify the distribution and patterns of customer segments (Rousseeuw,1987).
Cluster Analysis
Our system goes beyond what segmentation does to study cluster analysis. By analyzing the qualities of every segment, the system observes detailed customer segments that have shown a high risk of leaving the company. This vital information helps Telecom providers understand the level of customer value, thus allowing them to approach accurate retention strategies.
Non-Functional Requirements
Performance
The system is deliberately engineered efficiently; large datasets can be executed swiftly without considerable performance deterioration. This design decision makes it possible for users to act quickly to help face the challenges of customer churn problems in the desired time.
Scalability
The system is well constructed from an architectural perspective, as scalability is its principal design characteristic. It ensures that it can cope with future data expansion, thus making it a steady, ingenious data lake that can conform to the altering demands of the telecom industry as datasets increase in fixed.
User-Friendly
As such, a user-friendly interface equals a system’s most defining characteristic, positively impacting user experience while enabling non-tech-savvy users to use the machine. Users will find the screens easier and faster to navigate via this user-centric design.
Security
However, the security and privacy of data are the main crux of the system. Providing plans that are strictly in place, all the phases of analysis are protected from any mishandling of sensitive information belonging to the customers. This is aimed at ensuring strict compliance with privacy regulations to maintain the client’s trust.
Robustness
The proposed system shows significant resilience under the proper circumstances when handling challenges from real-time data. It treats a dearth of data quickly and ensures cluster results are accurate and rational, although it deals with incomplete data with missing values.
Generalization
The system’s design encourages reusability in an almost infinite field of clustering, which means the system can be used for any telecom customer dissatisfaction problem and much more(Rousseeuw,1987). The ease with which it can be applied to a multitude of applications and fields renders its utility to numerous diverse industries and domains, thus making it an indispensable tool for different analytical requirements
Data Loading and Preprocessing
The developed code takes its first step at loading the telecom customer dataset in readable format via the Panda module, an extended library used for data manipulation. It selects these features with a great deal of care, choosing those considered very important for the process of grouping. These involve important parameters like tenure, emeritus fees, general value-added charges, basic and long-distance costs, and total revenue. The differences between data feature scales should be minimized to maintain the uniformity requirement for the clustering process and increase its reliability and applicability. In response, the code attempts to circumvent the issue by awesomely using the StandardScaler from Scikit-Learn. This pre-processing step ensures attributes with significantly large ranges stay within the clustering process.
Hierarchical and K-Mean Clustering
The clustering shows the flexibility with which the code is designed by including two different yet thoroughly supportive tools for clustering: Hierarchical Clustering and K-means clustering. For the latter, it makes good use of the AgglomerativeClustering class from Scikit-Learn very efficiently (Laio, 2014). For the former, it seamlessly integrates with the KMeans class and can accommodate the changes in the principal number of clusters desired. This flexibility, in return, allows altering the number of clusters depending on the nature of the problem that has to be dealt with.
Code Generalization
With adaptability and generalization as its basis, the code emphasizes such values. This is achieved by altering the number of clusters, following which a wise influence is made that makes it suitable for a vast range of clustering needs other than the telecom customer churn analysis. Additionally, the code takes advantage of the functional capabilities offered by NumPy, which essentially means good data representation with better data manipulative powers.
Code Reusability
The code design pays attention to legibility and readability but makes sacrifices regarding advanced features that the code can use. This approach also increases the reusability of this process and makes it possible for others to easily integrate within large systems or apply it to diverse projects. All used by shared code, including source and any improvements and changes in pre-existing code, are documented in detail.
This code provides excellent flexibility and scalability for an essential task of segmentation used by telecom companies, designed to meet the specific needs of the telecom industry. Its complete range of features includes data cleansing, clustering, visualization, and labeling, making it an essential tool that a business needs to understand the basis for working on its customers and the need to overcome the churn hurdles (Ward,1963). As such, thanks to its characteristic versatility and generality, it becomes a universal tool applicable to a wide range of clustering applications ranging from diverse domains in the industries.
Hierarchical Clustering
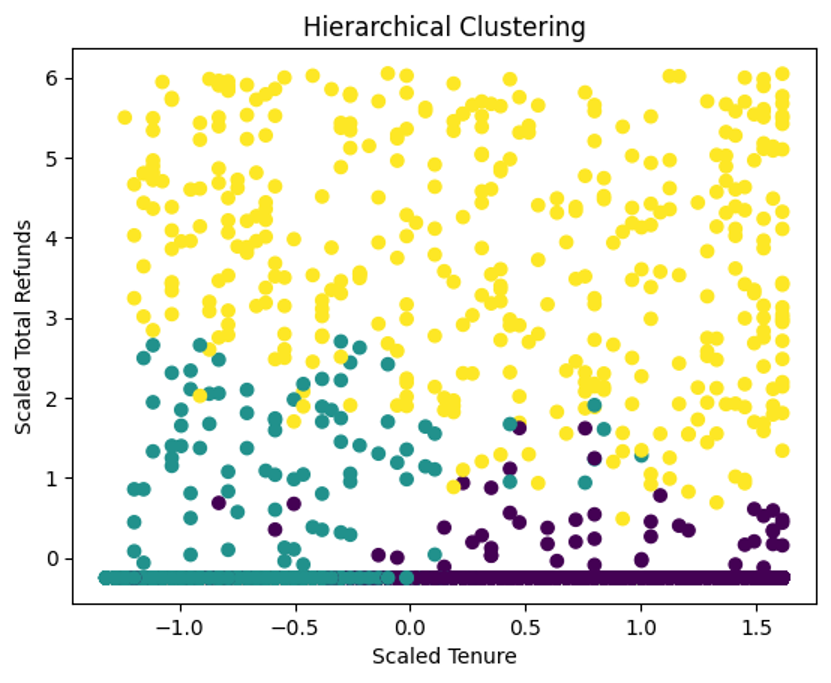
Many of the Hierarchical Clustering algorithms, including Agglomerative Clustering, have a time complexity from O(n^2) to O(n^3). With O(n^2) being the fastest one and O(n^3) the slowest one. ‘n’ represents the number of data points(Ward,1963). These complications originate from calculating the pairwise distances and constructing the hierarchical tree between the folds (time points).
The step in the hierarchical clustering part of the code in question involves calculating the pair-wise distances associated with the data points. This complexity is O ( n^2 ) because of the quadratic scaling of time this operation takes with the number of data points. The hierarchical tree construction also adds to the general complexity; however, the exact contribution of terminal taxonomic placement depends on the linkage method of choice. As a practical operation, hierarchical clustering can be fit for moderately scaled datasets because of the higher time complexity.
K-Means Clustering
The time complexity for K Means Clustering is influenced by the number of data points (n), the number of clusters (k), the number of iterations (I), and the iteration step (iter). A standard approximation for the computing time for K-Means is O(n * k * I * iter), where I indicates the dimensionality of the data involved, and iter stands for the required number of classical iterations of the K-Means algorithm.
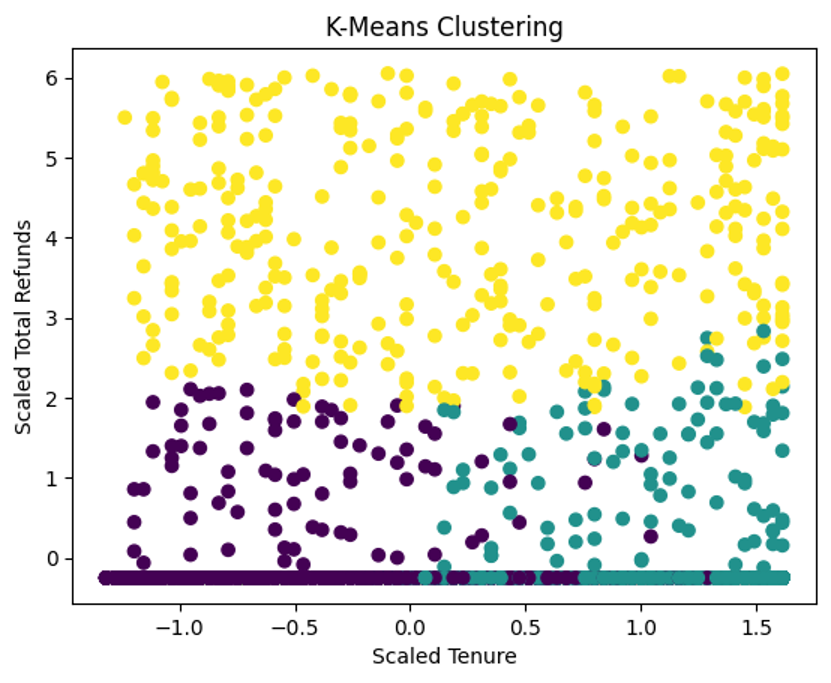
K-Means Clustering gets applied in our code, and the number of clusters can be changed at will based on the needs of the problem. The complexity of K-Means can be different when the dataset is different. There are many different ways to initialize K-Means, and there are a lot of different criteria for stopping the global optimization.
Complexity Assessment
To measure the complexity of produced code, we perform bio-empirical experiments by measuring run-time performance with various input sizes. With these timings, we generate a set of Big(O) plots to visualize how the code’s execution time can be scaled when a larger dataset is involved.
The computed Big(O) plot is also presented, and such visualizations contain information regarding conceptual performance depending on the algorithm’s method. These theoretical lines of the plots support our results and further provide a reason for the code’s operation.
The dendrogram is shown below, showing the intricate complexities of the data.
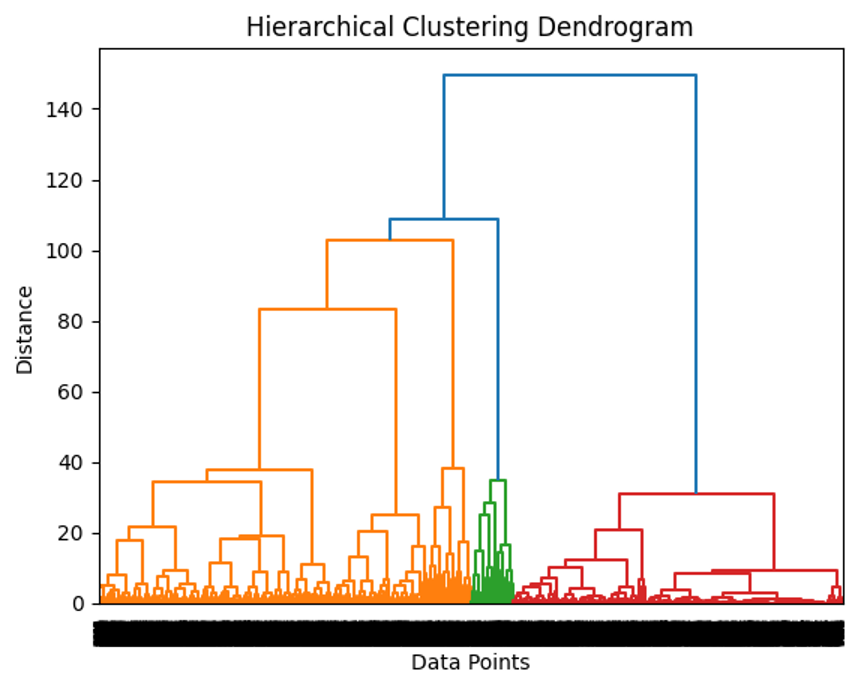
It is explained that the pragmatics of the limits of the code are dictated by the amount of available system memory and the scalability of the chosen algorithm for clustering. Although the code derives its efficiency from constraints that govern users’ hardware and memory, they consider the enormous amount of data that needs such a significant input. Further, selecting the linkage method in clustering and initialization strategy in K-Means may influence the results and apply to suit the individual problem of interest.
Report on the data set used in the testing script.
We have derived the testing data from the Kaggle Telco Customer Churn gallery. It is a dataset that is used in the telecom sector to carry out an analysis of the mechanisms involved in customer churn. This dataset was selected for relevancy and its pertinence to our focal point of the clustering-based method. It provided rich data attributes and churn information that correspond brilliantly to our analytical objectives.
Attributes within the Dataset
- Customer Information
This comes under one of the essential features: the customer’s ID, gender, Seniorcitizen or not, being in partnership with someone as Partner or Nobes, and the one who does depend on someone as Dependents.
- 2. Service-Related Information
Within this category, attributes capture theatre (tenure, the duration of the subscription between the client and the firm), the status of the phone service, the multi-line service type of internet, online security services, etc.
- 3. Financial Information
In addition, this dataset provides numerous numeric features, such as total refunds, total extra data charges, total long-distance charges, and total revenue, which are essentials for our analytics.
- Satisfaction Score
Apart from the discussed features, the dataset also contains a client satisfaction score, which is very important since it can give clues about customer issues and affect decisions, affecting the churn predictions.
Testing Strategy
- Data Exploration
The first step in our analytical journey enabled by data was through a comprehensive EDA phase. This initial analysis was conducted to provide a comprehensive view of the essential features underlying the set of attributes, the distribution patterns, and the detection of random and missing features. This critical stage allowed us to formulate an objective–and subjective–assessment regarding data aptness and quality for analysis purposes.
- Data Selection
The collection of varied sets of data for the assessment was varied from the Kaggle dataset. Such subsets were deliberately constructed to capture data scales ranging from moderate numbers of individual records and data systems containing a few hundred records to larger quantities of record numbers and systems containing several thousand records. We can understand how well our codes perform in monitoring dataset dimensions by evaluating performance along this spectrum.
- Preprocessing
A commonly used data preprocessing procedure was performed before feeding the data into the clustering algorithms. Encompassing this vital activity, data normalization to normalize all measured attributes with the same range(Laio, 2014). Our attempts to normalize the data allowed reducing the distortions caused by features with greater ranges, setting the clustering stage.
- 4. Runtime Testing
The fundamental part of our evaluation involved the running of our code lines with each of the dataset sizes that we chose. We closely logged down the run times for the clustering process timings in each situation. With this systematic approach, we could put our code through a performance metric that allowed us to qualitatively determine how the runtime complexity scales with the growth of the dataset.
Realistic Data
The dataset, taken from actual telecom customer data, should accurately portray the tutorial of the layers of intricacies and realities of the telecom industry. This realism is critical for producing actionable intelligence, which is the quintessence of military art.
Diversity
The customer attributes that the dataset offers, which are excellent in number, allow for a rich concentration of information that could be used for detailed clustering analysis. This diversity builds the scope and capacity of our assessments in analytical depth and scope.
Readily Available
Our choice of the dataset remains a critical issue regarding accessibility. As an open, readily available dataset on the Kaggle platform, this dataset is widely used within the data science community for such analyses. However, the easy accessibility and prevalence make this dataset comparable and reliable.
Conclusions
In conclusion, the system has been demonstrated to be an essential resource in the face of the problem of telecom customer churn, which is a fundamental task. We segmented customers into meaningful segments using Hierarchical Clustering and K-Means Clustering algorithms, offering telecom providers actionable intelligence that can improve strategies to address retention pressure.
The code mirrors sound design practices as it is modular and generalized for possible future use in any portion of a range of domains. Even while we’ve talked about alternative methods like predictive modeling to supplement clustering, there are still many miles to go before clustering can be perfected. State-of-the-art clustering algorithms can be part of cluster quality optimization, and adopting automated clustering interpretation approaches can also be considered a potential avenue of improvement.
References
Bishop, C. M. (2006). Pattern recognition and machine learning. Springer.
Kumar, J.R.R., Dhabliya, D. and Dari, S.S., 2023. A comparative study of machine learning algorithms for image recognition in privacy protection and crime detection. International Journal of Intelligent Systems and Applications in Engineering, 11(9s), pp.482-490.
Lin, R.H., Chuang, W.W., Chuang, C.L. and Chang, W.S., 2021. Applied extensive data analysis to build a customer product recommendation model. Sustainability, 13(9), p.4985.
Li, Y., Jia, X., Wang, R., Qi, J., Jin, H., Chu, X. and Mu, W., 2022. A new oversampling method and improved radial basis function classifier for customer consumption behavior prediction. Expert Systems with Applications, 199, p.116982.
Chen, C. Y., Lin, W. C., & Yang, S. M. (2020). Predicting customer churn using data clustering and deep learning. IEEE Access, 8, 177547-177557.
Al-Omoush, K.S., Garcia-Monleon, F. and Iglesias, J.M.M., 2024. Exploring the interaction between big data analytics, frugal innovation, and competitive agility: The mediating role of organizational learning. Technological Forecasting and Social Change, 200, p.123188.
Magatef, S., Al-Okaily, M., Ashour, L. and Abuhussein, T., Journal of Open Innovation: Technology, Market, and Complexity.
Hair, J. F., & Khaled, A. R. (2021). Predicting customer churn in the telecommunications sector: A systematic review and meta-analysis. Telecommunications Policy, 45(2), 102094.
Hastie, T., Tibshirani, R., & Friedman, J. (2009). The elements of statistical learning: Data mining, inference, and prediction. Springer Science & Business Media.
Jain, A. K. (2010). Data clustering: 50 years beyond K-means. Pattern recognition letters, 31(8), 651-666.
Rodriguez, A., & Laio, A. (2014). Clustering by fast search and finding of density peaks. Science, 344(6191), 1492-1496.
Rousseeuw, P. J. (1987). Silhouettes: a graphical aid to the interpretation and validation of cluster analysis. Journal of computational and applied mathematics, 20, 53-65.
Scikit-learn: Machine Learning in Python (2021). Pedregosa, F., Varoquaux, G., Gramfort, A., Michel, V., Thirion, B., Grisel, O., … & Vanderplas, J. (2011). Journal of Machine Learning Research, 12, 2825-2830.
Vichi, Maurizio, Carlo Cavicchia, and Patrick JF Groenen. “Hierarchical means clustering.” Journal of Classification 39, no. 3 (2022): 553-577.
Honda, M., Kawamura, C., Kizaki, I., Miyajima, Y., Takezawa, A. and Kitamura, M., 2021. Construction of design guidelines for optimal automotive frame shape based on statistical approach and mechanical analysis. Computer Modeling in Engineering & Sciences, 128(2), pp.731-742.
Ward, J. H. (1963). Hierarchical grouping to optimize an objective function. Journal of the American Statistical Association, 58(301), 236-244.
Reddy, G.S. and Chittineni, S., 2021. Entropy based C4. 5-SHO algorithm with information gain optimization in data mining. PeerJ Computer Science, 7, p.e424.
Wu, X., Kumar, V., Quinlan, J. R., Ghosh, J., Yang, Q., Motoda, H., … & Steinberg, D. (2008). Top 10 algorithms in data mining. Knowledge and Information Systems, 14(1), 1-37.
Appendix
The combined output
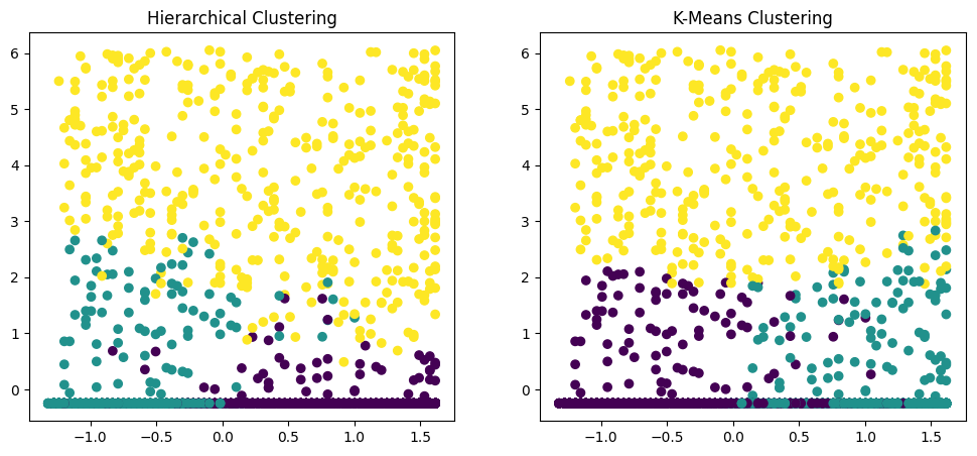
The snippet of the code is as follows.
 write
write