Introduction
The desire to improve visual recognition with the unlabeled has attracted the interest of various researchers in computer science. Various studies have been conducted to bring the ideas of different experts on the topic. Therefore, the proposal explores the ideas presented in secondary sources on the techniques for enhancing visual recognition with unlabeled data. The introduction section is divided into various subsections, including the background of the research, which discusses the technological areas that the study will be working in. The other subsection is the scope of the research which identifies the problem that the research is looking at, the critical research gap and the primary research the study is conducting. The usefulness of the research and the parties that would be interested in the research. The section also analyses the limitation of the research and the ethical issues that the researcher would encounter during the study.
The Background of the Study
The paper discusses the methods for improving visual recognition with unlabeled data. The research is motivated by the fact that human learning systems have high data efficiency, and therefore it tries to create the techniques that will make machines attain efficiency. In most instances, the vision systems of most technologies depend on a massive amount of labelled data to promote accuracy in the tasks, which has proven not to be a scalable solution in the long run. Therefore, investigating the ways and the means of exploiting unlabeled data for in-depth network training has been a critical attraction area. The concept of visual recognition refers to the ability of computerised systems to identify images and objects. Computers can use various technologies in machine visions with the help of artificial intelligence software and a camera to achieve visual recognition. When discussing the concept of visual recognition using unlabeled data, it is essential to consider various concepts, including but not limited to the following.
Semi-Supervised Learning
The concept of supervised learning combines supervised and unsupervised learning. Semi-supervised learning uses varying portions of labelled and unlabeled data, where the labelled data is used in a smaller quantity. In contrast, the unlabeled data is used in large quantities, which provides both the supervised and the unsupervised learning while also eliminating the challenge of finding large volumes of the labelled data. The concept of semi-supervised learning focuses on the scenario when the significance of the data contains a label or target while another part is unlabeled.
It is expected that the semi-supervised model would yield a higher outcome in terms of improvement over the supervised model and which is trained on the labelled data if the distribution of the unlabeled examples contains essential information which is significant in the inferences of the predictive posterior (Ren et al., [1].). The following are critical when using the semi-supervised learning method—using the labelled data in small volumes to train the semi-supervised learning model. The other activity is using the data with unlabeled training data set to help in the prediction of the output, which are pseudo labels since their level of accuracy may be in doubt. The third activity uses the initially created pseudo labels to link the labels from the label training data.
Unsupervised and the Self-supervised Learning
The self-supervised model uses partial inputs of the supervisory signal that can help learn a better representation of the input. The methods support the basics in the data to aid in predicting what has not been observed in the hidden sections of the object. It is worth noting that data that has not been labelled is significant, and each feedback presented by every sample is extensive, therefore helping in learning more enhanced input. [Roy 2].). Acknowledges. The concept of supervised learning relies on data that has been annotated, and it further faces challenges such as the generalising of errors. Other issues faced include spurious correlation and attacks. Networks that have undergone training with supervised learning do not strive to learn the features that have been generalised and can get away through mapping memorisation since there is the availability of the ground truth.
Learning with Noisy Label
Learning from data where the labels face corruption is key to the pseudo-labelling strategies adopted for object detection. Face recognition would not give a perfect label on the unlabelled datasets. Therefore, a particular training sample must be assigned incorrect labels and re-training the visual recognition models using noisy labels. Consequently, the label noise significantly affects the performance of face embeddings obtained from face recognition models trained on a large dataset [2].
Research Scope
The study’s primary objective is to identify the ways of improving visual recognition with unlabeled data. The research gap to be addressed by the research is that most computer vision systems rely on vast amounts of labelled data to obtain a high level of accuracy when conducting their tasks. And this is not an optimal solution in the long run. Therefore, the proposal aims at improving the accuracy of computer vision systems with unlabeled data.
Limitations
The research will rely on secondary data. Therefore, it is essential to note that the researcher will not be involved in any form of experiments in data collection.
Time constraint. The study would be comprehensive as it will source relevant information from various secondary sources. Therefore, the study might face time limitations as multiple sources would have to be reviewed to enable the author to access relevant information.
Cost constraints: The study would rely on secondary data, creating no need for interviews. However, the researcher would be expected to pay for some books from websites such as Amazon, especially when the book in consideration is relevant to the proposal but is not freely accessible.
Ethical Issues
The consideration of the Data Protection Act during the analysis of the data collected.
The issue of intentional misinterpretation of the data collected.
Honesty and integrity during the reporting of the data collected.
The need for ethical approval from the university before the commencement of the study.
Literature Review
The idea of improving visual recognition with unlabeled data has attracted the attention of various researchers. As a result, multiple studies have been conducted to help learners understand ways visual recognition can be improved with labelled data. Therefore, this section of the proposal presents the relevant ideas of different authors on the concept of visual recognition.
The Self-Supervised Learning
Ohri et al. [3] present a vivid analysis of deep neural networks (DNN) in self-supervised image recognition. The study’s primary objective [3] was to analyse the concept of self-supervised learning that can use labelled data to revolutionise the computer vision field. The model permits the network to learn the features, which allows for the conducting of tasks such as image classification, object detection and object segmentation. The critical learning schemes include semi-supervised learning. The strategies combine both supervised learning and unsupervised learning. The method undergoes training on fraction data which has undergone manual labelling. Once the label has undergone significant training, it is used to predict the remaining unlabeled data.
Other existing learning schemes include the weakly-supervised learning and supervised learning from the noisy label. The semi-weak supervised learning adopts the student-teacher network, which uses weakly and semi-supervised learning. Incremental learning is also a critical learning scheme in machine learning. The goal of the learning scheme is to aid in the continuous learning and the solving of new tasks while remembering both the new tasks and those that had been learned in the past Zeki [4].).
Additionally, it is worth noting that self-supervised learning allows reconstructing from an image that is partial and a view of an image that has been altered. Taye [5] notes that the ConvNet helps in predicting an image that is considered correct from a view that has been altered. The colourising image’s subject is an instance of a pretext task that allows the ConvNet to predict the probable colour of the image from the grayscale image. The ConvNet learns an image representation by predicting the colour value of an input grayscale image. The network gets some training on the numerous pairs of coloured and the images in the grayscale at the lowest cost because they are available. Grayscale. To address the task of colourisation, the network helps in the recolonisation of various objects that are in the image and groups parts that had been recognised together and also tints them using the same colour, which allows for the learning of the input image in the activities of performing the pretext tasks that is key in performing the downstream task.
The self-supervised method aids in the generation of images. The supervised learning method that is image generation based is adopted in the representation of images that allows for the generation of images using the Generative Adversarial Network (GAN). The GAN helps create realistic images of an individual’s face, which have close similarity with the original image but have been recorded in the input database.
The spatial context prediction helps in exploiting the existing special relationship among the image parts. Contest prediction is a crucial pretext task that helps to predict the correct spatial orientation of patches that have been randomly chosen. It is worth noting that the network gets training on the patches and those that are neighbouring and have chosen to create the large corpus of the unlabeled data. The training aims at assigning similar representations to semantically similar patches. For instance, in the image below, there should be a semantical similarity between the representation of the cat’s ear coming from different cat images. The network lean-to relates patches similar to similar marching principles. The figure below shows the spatial context prediction.
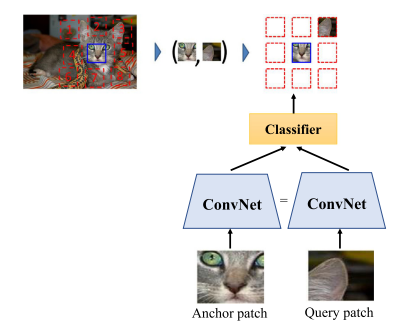
The Versace Method
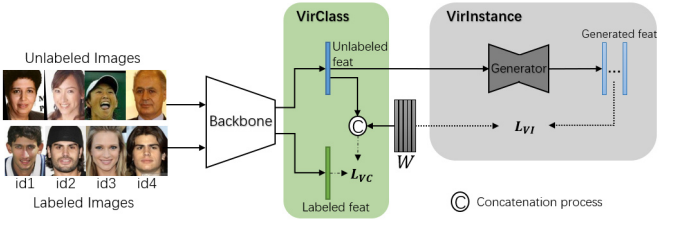
The study by Li[6] et al. proposes VirFace as an essential visual recognition method. The method allows the effective exploitation of unlabeled data in face recognition. The research notes that the semi-supervised technique, which focuses on the generation of pseudo labels or the minimisation of softmax classification probabilities of the data that is not labelled, fails to work on the not labelled data as expected, especially when the data is shallowed. Li et al. [6] note that the VirFace consists of components such as VirClass and VirInstance.
The proposed method help in injecting unlabeled data as new identities into the space that has already been labelled to help enlarge the inter-class distance. The virtual class gives the unlabeled data a virtual identity in a mini-batch. Since the unlabeled data is complex to find the sample from the identity in the mini-batch, it is shallow. It is complex to find samples from the same identity in the mini-batch; every unlabeled feature can be substituted to help represent the centroid of the virtual class. Can be a substitute to represent the centroid of its virtual class. The centroid is then injected into the labelled space and maximises the angles between the labelled samples and the centroids of the virtual classes to help enlarge the inter-class distance. It is essential to dynamically update the virtual classes and mini-batches to help reduce the storage cost and computational consumption.
The instance further sparse the static class by providing the virtual assistances sampled from the learned distribution of every identity. The instance helps in the generation of feature distribution of every virtual class. It maximises the distance between the labelled centroids and feature distributions of virtual classes to help enlarge the inter-class distance. Douglas et al. [7] note that the sampling distribution is close to the normal distribution according to the central limit theorem if the sampling number is large enough regardless of the original distribution.
It is also important to note that if all face features are treated as a full-face feature set, the features of every identity can be regarded as the sampling subset of the complete set following a large distribution form. To formulate the distribution of every virtual class more adequately, it is essential to randomly sample various virtual instances from the distribution of every virtual class. The virtual instances from the same class represent the corresponding feature distribution, therefore helping maximise the distance between the labelled centroids. The feature distribution of virtual classes is the same to maximise the distance between the labelled centroids and the virtual instances of every virtual class.
Fuentes et al. [8]. discussion on visual recognition with unlabeled data focuses on face recognition using unlabeled data. [8], notes that the main idea for using unlabeled data n visual recognition is to improve classifier accuracy when a small set of labelled examples is available. The researchers apply the eigenfaces technique to help reduce the dimensionality of the image space and ensemble methods to obtain the classification of unlabeled data. The study notes that multiple practical algorithms for unlabeled data have been proposed. The proposed algorithm includes the co-training algorithm, which is targeted to training tasks where every instance can be described using the help of two independent sets of attributes. The other proposed algorithm is based on the combination of the naïve Bayes classifier and the expectations maximisation for text classification. The other method combines active learning and the EM, the pool of unlabeled data. The query-by-committee is used in the active selection of examples for labelling. Then EM with the naïve Baya model further improves the accuracy in classification through the concurrent estimation of probabilistic labels for the unlabeled examples that are remaining.
The research by Nguyen et al. [9] investigates semi-supervised learning with minimal instances-level labelled images and the many unlabeled images. The study proposed the expectation-maximisation (EM) technique for semi-supervised object detection with unlabeled images. The method provides an end-to-end semi-supervised training that helps in integrating EM in every iteration for classification optimisation and in every epoch for the localisation optimisation. In the early stages, the model uses the instance-level labelled data to help train the detectors. The other stages adopt the combination of the labelled and the unlabeled data to help improve the performance of detectors. The literature also treats the object detection model as a latent variable where the instance-level labels are missing values. The research findings indicate that the use of the EM and the unlabeled image to help in the optimisation of both the classification task and the localisation task is better than the enhancement of the classification task alone. The study also proposes using annotated images and then using the raw images to improve performance detection.
Research Questions
What are the methods of enhancing visual recognition with the unlabeled data?
What are the significant distinctions between the labelled and the unlabeled data?
What are the barriers to accuracy in visual recognition with labelled data?
Methodology
The research methodology section of the proposal highlights the various strategies adopted when conducting the study. The section discusses the preparations that would be undertaken, the initial analysis that the researcher would undertake, the methods for collecting the data and the technique for analysing the data collected. Other section components include evaluation, reporting results and conclusions and risk analysis.
Preparation
The study will immensely rely on secondary data. Therefore, my preparation will focus on how to collect the secondary data. Therefore, I will do a preliminary search for information to determine whether there is adequate information that will help me set the context of the study. I will look up critical words and the appropriate titles in the library’s reference collection. Additionally, I will locate the materials that I plan to use in the study, further evaluate the sources, and proceed to make notes. When making notes, I will ensure that I document all the sources that I have consulted, even if there is a chance that I may not use the particular source.
Initial Analysis
I will analyse the themes of the secondary sources to determine how significant they are to the objectives of the study. Besides, I will analyse the keywords used in the selected sources to reduce the volume of the sources that I would use in the study. The keywords that I will be checking in the secondary sources are unlabeled data, visual recognition, and machine learning.
Data Collection
Data will be collected through a systematic literature review. The data collection technique helps examine the data and the authors’ findings relative to particular research questions (William et al. [10].). Data would be collected using the systematic literature review because the data used in the study would be secondary. Besides, the systematic literature review technique would give the researcher a comprehensive overview of the literature related to the objectives of the research. Additionally, the researcher settled on the data collection method because it would help the researcher synthesise previous work to strengthen the foundation of knowledge while considering the concepts of transparency and bias reduction.
Data Analysis
The data collected would be typed and stored in new folders on my computer. The data will be stored in electronic form. Data will be protected from any external or unauthorised person by introducing passwords on the computer. The researcher will use the qualitative content analysis technique to analyse data. The themes would be analysed by assigning preliminary codes to the data to describe the content. Besides, patterns will be searched in the codes across various sources. The other activity would be the review of themes and defining the themes. Additionally, the researcher will be able to determine meaning from the results by analysing the different results from different authors (Feng et al.
| Risk | Likelihood | Severity | Mitigation |
| 1 | Time overrun | Likelihood | Have a timetable for task completion and set a reminder to notify the researcher when it is time to complete a task. |
| 2 | Budget overrun | Likelihood | Seek a project sponsor |
| 3 | Unable to access a valid source freely | Likelihood | Use of other academic databases |
| 4 | Psychological risks such as anxiety and altered behaviour. | Likelihood | Seek advice from experienced researchers. |
[11].).
Reporting Results and Conclusion
I will report the results through presentations. I will make sure that I include the data analysis and the interpretation details. To reach a coherent stop, I will ensure to inform the audience that I am about to conclude and give them an overview of my presentation on the topic before bringing it to a stop.
Project Planning and Scaling
| ID | Dissertation task | Weeks | Date |
| 1 | Preparation and the existing analysis | One week | June 1st 2022 |
| 2 | Making critical updates on the literature review | Two weeks | June 14th h, 20202 |
| 3 | Completing the dissertation | Three weeks | July 7th, 2022 |
| 4 | Prove reading the final dissertation | Three days | June 12th, 2010 |
Risk Analysis
Ethical Approval
The research methodology area needs independent approval. This is because it will allow me, as the researcher, to interact with external parties. It would be vital for me to uphold high ethical standards to prevent the infringement of the set ethical policies. My ethical obligations as the researcher would include the following. They are obtaining permission from the university before commencing the research. Therefore, the researcher would visit my professor to get permission to conduct the research. The other obligation that the researcher would be required to maintain honesty when reporting the data collected and conducting the research. Therefore, the researcher would ensure that all the members can access the document and reference the source of the data present in the study.
Additionally, the researcher would be required to avoid any form of misinterpretation, especially those done intentionally. The research will ensure that there is consistency in the work presented. Therefore, it would be important that all the data be carefully examined and the records for each examined data be appropriately maintained. That research would be required to promote openness, especially during data sharing. The researcher would ensure that there is no harm to the respondents. Therefore, the researcher will ensure that the respondents’ welfare is considered to promote proper decision making during the study. It would be important that the researcher avoid discrimination against the respondents.
Action to Obtaining Ethical Approval
The following actions will take place. I will assemble my application document package. The package includes the application form and the supporting documents. The mailing of the application package to the head of the learning institution, assessing the risks and allocating the possible review pathways. The other activity will be reviewing the application by the ethics reviewing body. The body will review the ethics application, request changes if needed, and proceed to approve the application after being convinced that the changes demand have been satisfied. The last activity is the notification of approval to allow the commencement of the project.
Conclusion
The study focuses on improving visual recognition with unlabeled data. The proposal identified various methods for improving visual recognition, including self-supervised learning, the VirFace method and the semi-supervised learning method. The study will adopt the systematic literature review in data collection in the research method. The collected data would be stored in the computers in their electronic form. Data reporting will be done through presentations. The researcher would also seek ethical approval. Various actions that would be undertaken include assembling the application documents, reviewing the application by the ethics reviewing body, and receiving notifications of approval to allow the commencement of the project.
References
[1]. Ren Z, Yeh R, Schwing A. Not all unlabeled data are equal: Learning to weight data in semi-supervised learning. Advances in Neural Information Processing Systems. 2020; 33:21786-97.
[2]. Roy Chowdhury A. Improving Visual Recognition with Unlabeled Data.
[3]. Ohri K, Kumar M. Review on self-supervised image recognition using deep neural networks. Knowledge-Based Systems. 2021 July 19th; 224:107090.
[4]. I. Zeki Yalniz, Hervé Jégou, Kan Chen, Manohar Paluri, Dhruv Mahajan, Billion-scale semi-supervised learning for image classification, 2019, arXiv preprint arXiv:1905.00546
[5]. Taye GT, Hwang HJ, Lim KM. Application of a convolutional neural network for predicting the occurrence of ventricular tachyarrhythmia using heart rate variability features. Scientific reports. 2020 April 21st;10(1):1-7.
[6]. Li W, Guo T, Li P, Chen B, Wang B, Zuo W, Zhang L. VirFace: Enhancing face recognition via unlabeled shallow data. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2021 (pp. 14729-14738).
[7]. Douglas C Montgomery and George C Runger. Applied statistics and probability for engineers. John Wiley and Sons, 2014
[8]. Martínez C, Fuentes O. Face recognition using unlabeled data. Computación y Sistemas. 2003 Dec;7(2):123-9.
[9]. Nguyen NV, Rigaud C, Burie JC. Semi-supervised Object Detection with Unlabeled Data. InVISIGRAPP (5: VISAPP) 2019 Feb 25 (pp. 289-296).
[10]. Williams Jr RI, Clark LA, Clark WR, Raffo DM. Re-examining systematic literature review in management research: Additional benefits and execution protocols. European Management Journal. 2021 August 1st;39(4):521-33.
[11]. Blumzon CF, Pănescu AT. Data storage. IN Good Research Practice in Non-Clinical Pharmacology and Biomedicine 2019 (pp. 277-297). Springer, Cham.
 write
write