Abstract
The paper dealt with genre analysis of the linguistic features. Genre Analysis has become one of the major influences in different places, including the professional and unprofessional areas. The two corpora selected in this study were the conversations and academic articles. AntConc version 4.0.6. was used to analyze word frequency, frequency of common phrases, keywords being used, and position of the targeted word in a text between the corpora. Quantitative analysis was done to ensure that the accuracy counting of every feature by recounting in each essay is reached. The frequency rates were then normed as 1000 words to generate a reliable foundation for comparing the texts of varying lengths. SPSS software was used to carry out inferential analysis for comparing the frequency rates of the linguistic features between the groups. According to the results and analysis in this research study, there was no significant difference (p<0.05) at a 95% confidence level in the linguistic features being analyzed in this research study. The main reason that could have led to these results is the use of conversation that was professional as that of the academic article used. Therefore, it is revealed that there is no distinction between the written text and transcribed conversation if both corpora are presented professionally. Finally, if the guidelines are observed when having a professional conversation will have no variation in the frequency of words’ appearance, the frequency of the position of the specific word being used in a text, keywords, and the frequency of the common expression being used in a given text.
Introduction
Genre Analysis has become one of the significant influences in different places, including the professional and unprofessional areas. Hyland (2004) described the genre as a term for putting texts in the same category, representing how writers usually use language to respond to recurrent circumstances. In addition, Swales (1990) described the genre as a piece of communicative occasions, with members sharing a part of communicative determinations. Genre analysis greatly influences various disciplines like law, science, arts, business, engineering, and other scopes of professionalism in teaching and learning institutions. Besides, genre analysis is of great importance in different organizations when it reaches to matters about information sharing in the company and how to carry out conversations within and outside the company. A comprehensive genre analysis will be shown and discussed in detail to distinguish between the academic article and the conversation by offering a vibrant clarification of how an expert should use English. Therefore, this study will focus on analyzing the linguistic features of the two corpora. The analysis of the two corpora will focus on the textual analysis for comparisons of features to the extent that supersedes human reading.
Furthermore, the analysis will deal with text structure using antconc software to compare the frequency of words and keywords and collocate between the two corpora. The analytical techniques used in this study were: keyword, N-grams tool, word list, and plot tool. These analytical techniques are crucial in contributing to uncovering discourse practices.
Some of the research questions that will be used for the analysis and discussion in this paper are:
- What is the linguistic difference between the conversations and the academic articles regarding the frequency of words in a corpus?
- What is the difference in frequency of using keywords per 1000 words between the conversations and academic articles?
- What is the difference in frequency of common expressions per 1000 words between the conversations and the academic articles?
- What is the difference in frequency where the specific word appears in a particular corpus per 1000 words between the conversations and the academic articles?
Methodology
This paper focuses on the two corpora: conversations and academic articles. The variations of the two corpora will be determined by genre analysis based on the linguistic features. Different kinds of corpora vary in terms of linguistic features from one another (Biber& Conrad, 2009). Therefore, the linguistic features that will be used in this study to distinguish between academic articles and conversations will be an analysis of the frequency of words, keywords, variation in everyday expressions, and the variation in the targeted word appearance as per 1000 words. Variations in the linguistic elements between the conversations and the academic articles will help answer the research questions listed above by analyzing differences in the frequency of words, keywords, variation in everyday expressions, and the variation in the targeted word appearance as per 1000 words. The data from each corpus will be obtained by selecting an academic article and transcribing a conversation between two people. The linguistic features will be located by underlining the targeted parts separately in every corpus. Genre analysis is significant (Yakhontova, 2018) as it helps understand how to communicate in different aspects of life and social backgrounds in writing. Understanding the genre analysis helps investigate all the features of a written message. Furthermore, genre analysis helps to understand and know the conventions of the message and its repeated, recognizable, and predictable features. Additionally, genre analysis helps to understand better and evaluate the written texts.
Several steps were involved in collecting the data and how they were analyzed. The first step started by selecting an academic article of about 1500 words. Out of the 1500 words, the first 1000 words are the ones that were used in this study. The other corpus, the conversation between two people in an interview, was chosen and transcribed. Then, the first 1000 words from the transcribed interview were the ones that were used in this study. The data from every selected corpus was obtained by analyzing the differences in the frequency of words, keywords, everyday expressions, and the variation in the targeted word appearance as per 1000 words. The analysis was done using a multi-dimensional (MD) analysis developed by Biber (1988). The tool has been used to analyze various linguistic features like the parts of speech, grammar, and other linguistic features (Conrad, 2002).
Coding features were used in the study by the Concordance, the selected text to be analyzed (Biber, 2006). According to Barlow (2004), it was preferred that Antconc Windows (Installer) (4.0.6) concordance software be used to count the linguistic features to be analyzed in this research study (Anthony, 2022). Additionally, the word list provided in Hinkel (2002) was used and searched for every word in the text analyzed to get an accurate count of the features.
Anthony version 4.0.6 was used to generate a list of the tokens of the searched word, and I went through each list for accuracy enhancement. The targeted word was checked thoroughly in every analysis that was carried out. For accuracy enhancement, every document was thoroughly checked for the miss-tagged tokens and adjusted the counts consequently. The variations for the tokens to be included in each linguistic feature count are based on the distinctions generated by Hinkel (2002) and other reliable English grammar of (Biber et al., 2002). Therefore, the identified linguistic features in the two corpora were done to check the existing differences between the two.
Quantitative analysis ensured the accurate counting of every feature by recounting it in each essay. The frequency rates were then normed as 1000 words to generate a reliable foundation for comparing the texts of varying lengths. Then the frequency rates of the two corpora, converted, and academic articles were then compared using non-parametric statistics. The non-parametric statistics were reliable due to the non-normal scattering of the data. According to the Analysis of Hinkel (2002), it was regarded to use the Mann-Whitney U test to compare the rankings above and below the median frequency rate for every linguistic feature in the same corpora among the categories. The medians were compared in every set of data instead of the means due to the outliers influencing the average frequency of the linguistic feature. Finally, SPSS software was used to carry out inferential analysis for comparing the median frequency rates of the linguistic features between the groups.
When the statistical results of the frequency analysis were obtained, the concordance analysis of the listings investigated the specific discourse aspects in which each of the significantly varied linguistic features was utilized. Grammar reference books were used to identify and classify every feature’s standard functions. Examples were checked from the two corpora to determine if the features were used similarly in conversation and academic articles. Also, the instances in which the linguistic feature was used in different ways aside from the atypical means.
Results
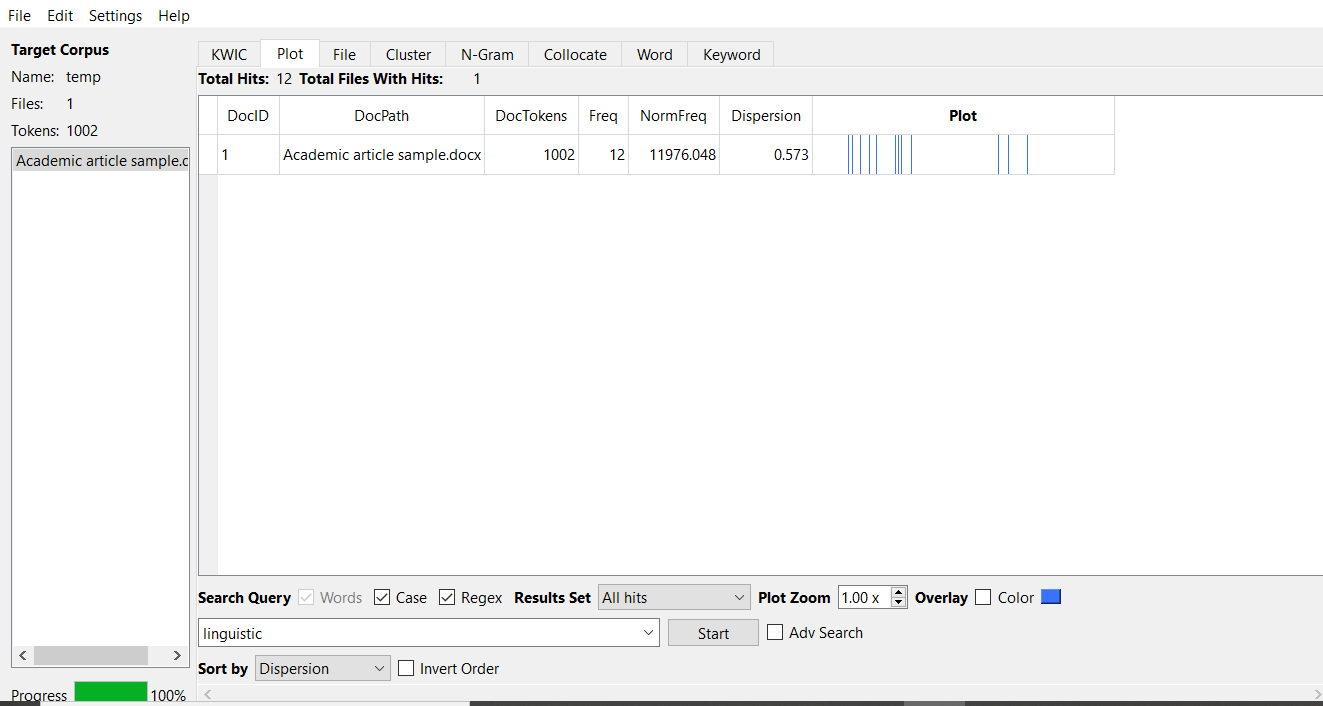
Table 1. Plot tool Analysis
| Attributes | Conversation | Academic Article |
| Dockens | 1017 | 1002 |
| Frequency | 6 | 12 |
| Norm frequency | 5899.705 | 11976 |
| Dispersion | 0.433 | 0.573 |
The results of the plot analysis between the conversation and the academic corpus indicate that there is a variation in terms of the frequency of the words being dispersed in the entire text. For instance, there is a difference in norm frequency (5899.705, 11976), frequency (6, 12), and dispersion (0.433, 0.573) in the conversation and academic, respectively.
Table 2. Wordlist Analysis
| Frequency of words | Conversation | Academic Article |
| The | 49 | 52 |
| To | 38 | 31 |
| Is | 29 | 23 |
In the word list analysis, the use of frequent words like “the,” “to,” and “is” had some variation between the conversation and the academic article. The rate at which the most appearing words occur in terms of frequency is higher in academic writing than in conversation. For example, the phrase “the” has appeared more frequently in the conversation than in the academic article (49 and 52), respectively.
Table 3. N-gram Analysis
| Conversation | Academic | |
| frequency | 3 | 4 |
| 3 | 4 | |
| 2 | 3 |
In this category, there is also a difference between the conversation and the academic article. For example, the frequency rate of the N-gram analysis (3 and 4) for the conversation and educational article, respectively.
Table 4. The Summary of the Analysis
| Conversation | Academic Article | p-value | Median | |
| Plot Analysis | 6 | 12 | 0.656
|
9 |
| N-gram Analysis | 3 | 4 | 0.101 | 3.5 |
| Wordlist Analysis | 49 | 52 | 0.765
|
50.5 |
Generally, table 4, shown above, summarizes the entire data and analysis of the research in table 4. Indicates that there is no variation across all the aspects analyzed. For example, there was no significant difference across the avenues, showing no variation in plot analysis, wordlist frequency, and N-grams analysis. The p-values of all the aspects were > 0.05 at a 95% confidence level. According to the ANOVA, this reveals that there is no variation between conversation and academic articles. The p-values of the plot analysis, N-grams analysis, and wordlist analysis were (0.656, 0.101, and 0.765). Therefore, even though there is the manifestation of variation in terms of values, statistically, there is no variation between conversation and academic paper text structure according to the analysis done.
Discussion
This research study based its analysis on the concordance tool. The concordance tool helps reveal how phrases and words are used in a corpus of writings (Anthony, 2012). Therefore, the frequency rate determination of the word lists based on linguistic features between the conversations and the academic article shows no statistical difference according to the results shown in table 4. This is discussed further below.
The frequency of words between the conversation and the academic article corpus has no difference. The reason that could not have led to this difference was that the conversation used in this research study was the interview between the retired president, Barack Obama, and the journalist, and both parties were conversing professionally. Besides, the same linguistic technique is being used to present the academic articles. Therefore, this research study reveals that if the conversation is made professionally and all requirements of formal communication are observed, there will be no difference in how the frequency of words can appear in a text. Additionally, the frequency of using keywords is also affected based on the appearance of the words in a text (Chafe &Tannen, 1987). Therefore, the wordlist tool helped to reach this conclusion since it helped to analyze if there is variation in terms of word frequency between the conversation and the academic article (Anthony, 2022).
The frequency of the typical expression analysis in this study also did not vary between the conversation and the academic article. Since there was a statistical insignificance difference (p>0.05) at the confidence level of 95%between the two corpora. The same assumption of using professional interviews in this research study could have led to no significant difference between the two corpora. Since when there is a conversation between individuals discussing a particular topic, they have to lean on a common phrase that will keep the discussion in the desired direction. The same case is observed in academic articles; if the article is handling a specific topic, it keeps on leaning on using a particular phrase to stick to the topic being discussed (Chafe &Tannen, 1987). It shows that if the conversation of individuals is made professionally by observing all forms and requirements of formal communication, there will be no difference in terms of the frequency of the phrases being used in the texts. The above conclusion was reached after analyzing the N-grams tool (Anthony, 2022).
Furthermore, the study revealed no difference between the conversation and the academic article regarding the position of the targeted specific words’ appearance in the text. Since the significant difference was insignificant (p>0.05) at a 95% confidence level. The targeted word in the text is the frequency of the keyword appearing in the given text. Therefore, the same assumption of using professional conversation and academic articles as the selected corpora is to analyze the difference in frequency of the targeted specific word in a text because both corpora observe the same guidelines in the text structure. The above results were analyzed by a concordance plot tool (Anthony, 2022).
In conclusion, there was no significant difference (p<0.05) at a 95% confidence level in the linguistic features being analyzed in this research study. The main reason that could have led to these results is the use of conversation that was professional as that of the academic article used. Therefore, it is revealed that there is no distinction between the written text and transcribed conversation if both corpora are presented professionally. Finally, if the guidelines are observed when having a professional conversation will have no variation in the frequency of words’ appearance, the frequency of the position of the specific phrase being used in a text, keywords, and the frequency of the common expression being used in a given text.
References
Swales, J. (1990). Genre analysis: English in academic and research settings. Cambridge University Press.
Hyland, K. (2004). Genre and second language writing. University of Michigan Press.
Biber, D., & Finegan, E. (1988). Adverbial stance types in English. Discourse processes, 11(1), 1-34.
Conrad, S. (2002). 4. Corpus linguistic approaches for discourse analysis. Annual review of applied linguistics, 22, 75.
Yakhontova, T. (2018). A linguistic and didactic model of teaching English research article writing to doctoral students. Inozemna Philologia, 131, 166-173.
Hinkel, E. (2002). Second language writers’ text: Linguistic and rhetorical features. Mahwah, NJ: Lawrence Erlbaum Associates, Inc.
Biber, D. (2006). University language. Philadelphia: John Benjamins Publishing.
Barlow, M. (2004). MonoConc Pro 2.0. Houston, TX: Athelstan Publications.
Biber, D., Conrad, S., & Leech, G. (2002). Longman student grammar of spoken and written English. Essex: Pearson Education Limited.
Anthony, L. (2022, January). Anthony Windows (Installer) (4.0.6) concordance software. Tokyo, Japan: Waseda University. Available from http://www.antlab.sci.waseda.ac.jp/
Anthony, L. (2012). AntConc (Version 3.3.2) [Computer Software]. Tokyo, Japan: Waseda University. Available from http://www.antlab.sci.waseda.ac.jp/
Chafe, W., & Tannen, D. (1987). The Relation between Written and Spoken Language. Annual Review of Anthropology, 16, 383–407. http://www.jstor.org/stable/2155877.
Appendices
Conversation Analysis
Source of the interview: https://www.bbc.com/news/world-us-canada-33646542
Appendix 1. N-Grams
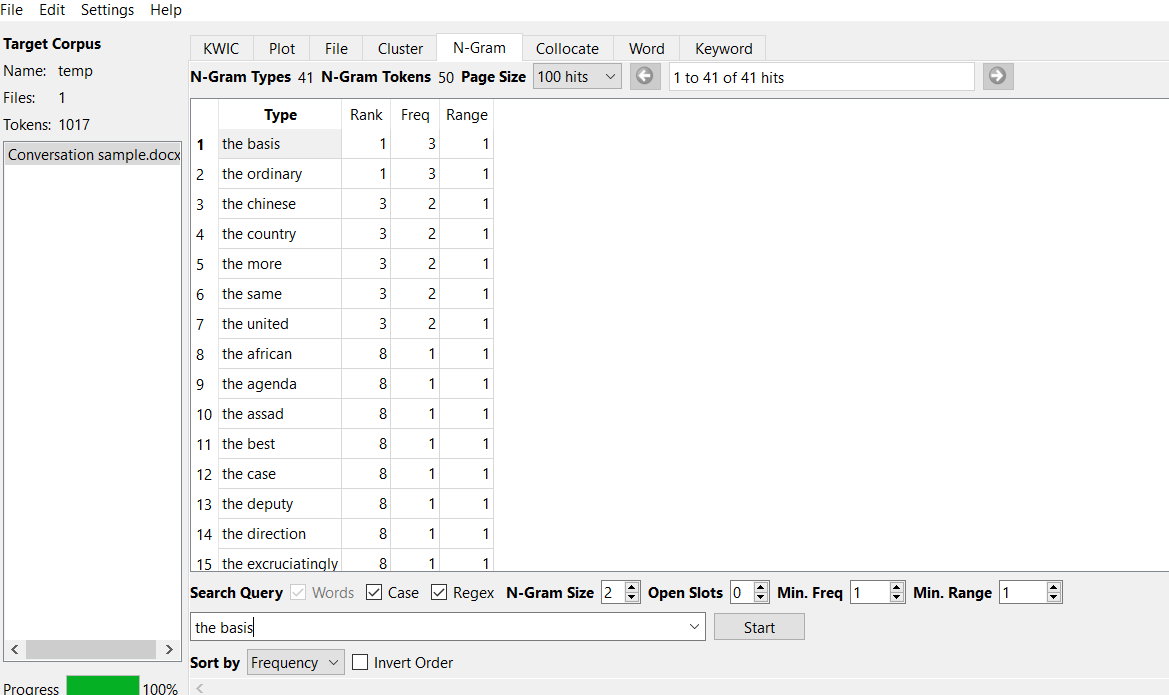
Appendix 2. Plot Analysis
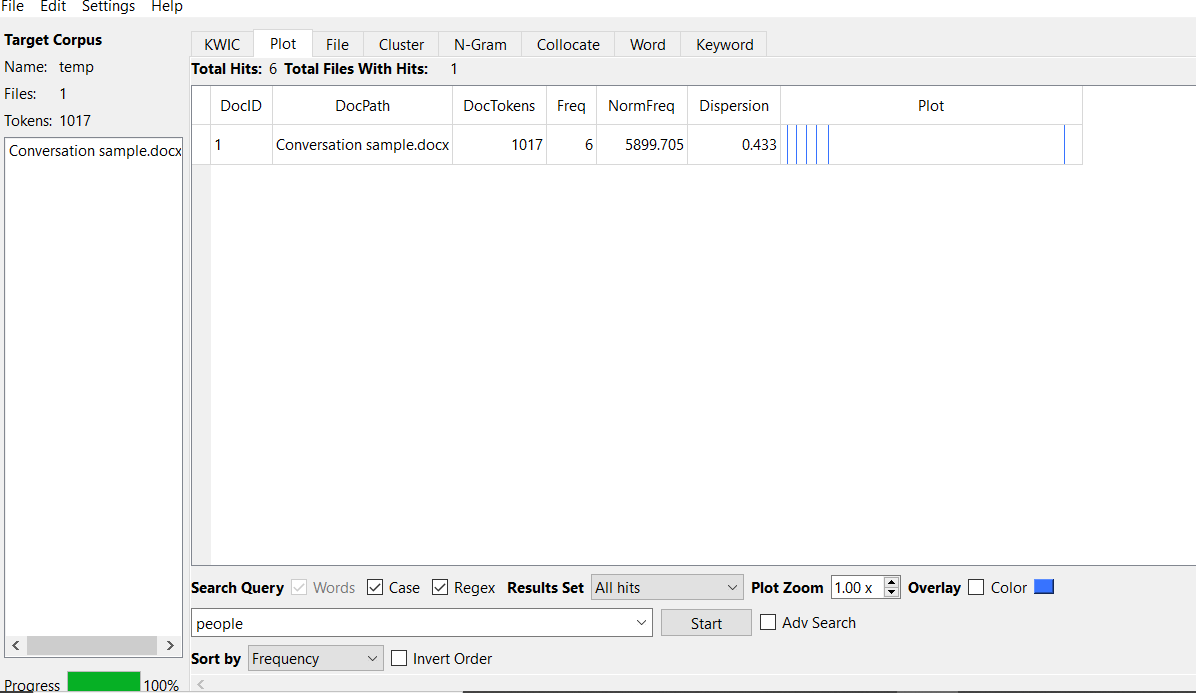
Appendix 3. Wordlist Analysis
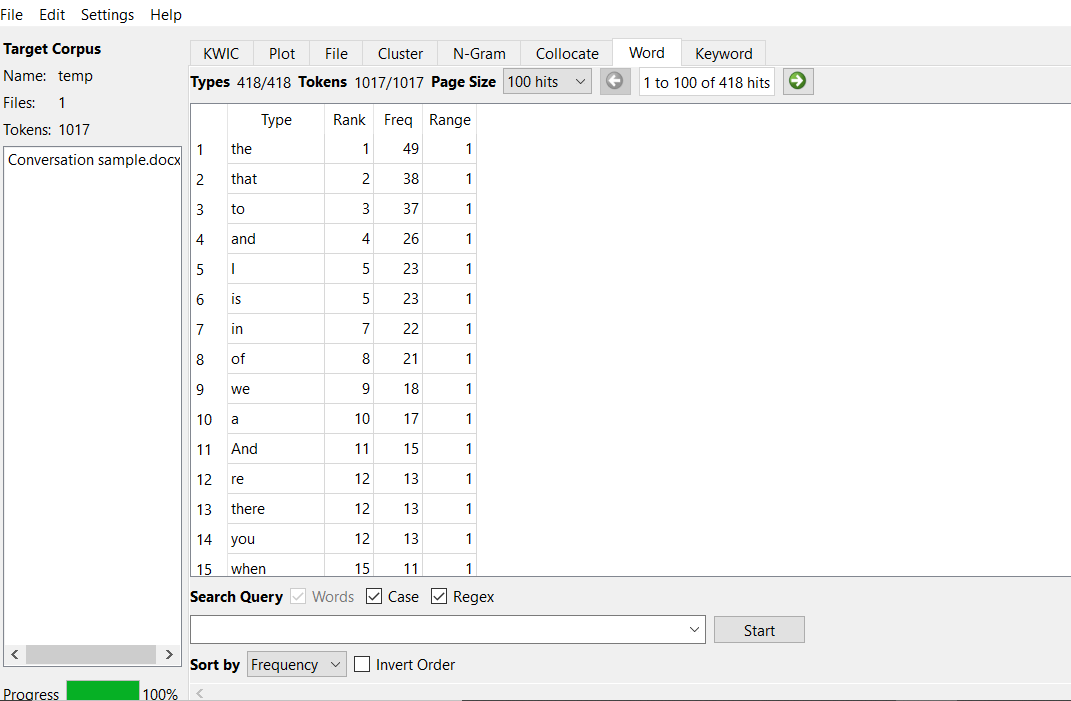
Academic Article Analysis
Appendix 4. Plot Analysis
Appendix 5. N-gram Analysis
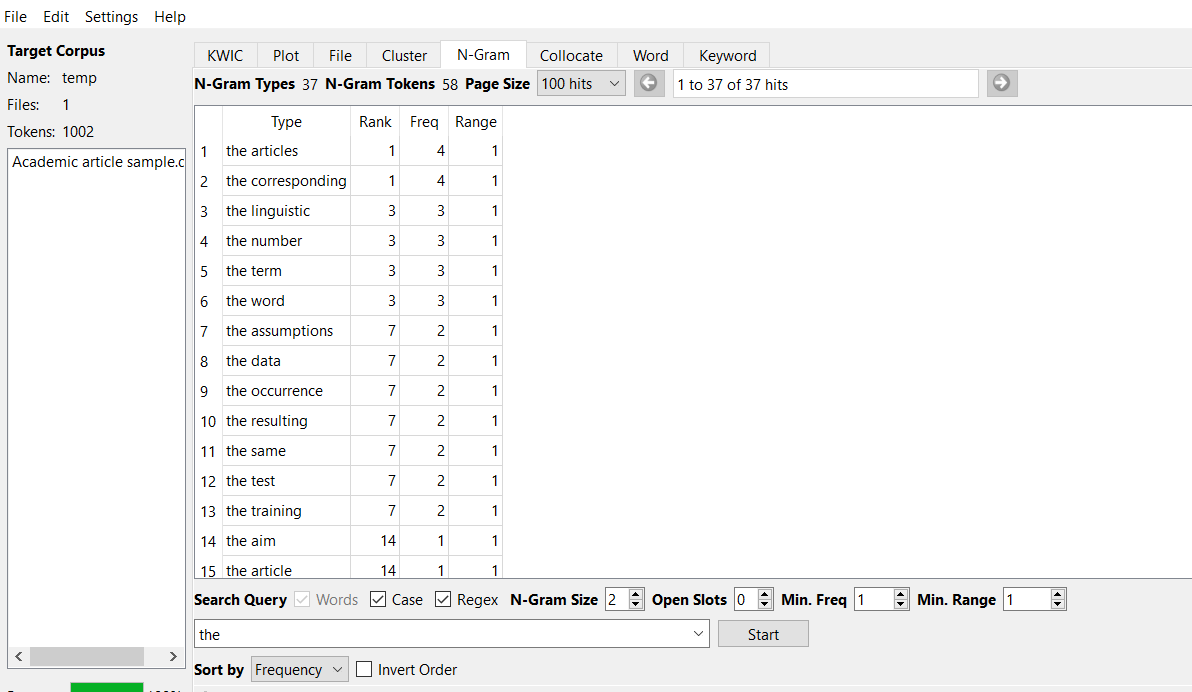
Appendix 6. Wordlist Analysis
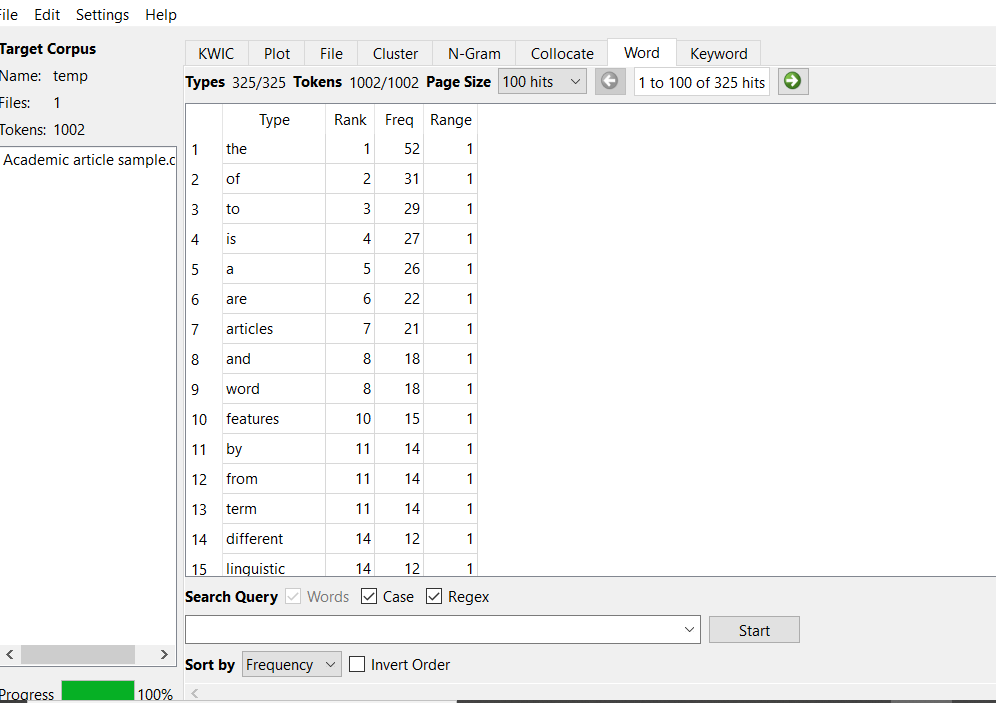
 write
write