Abstract: Nowadays, the global challenge of COVID-19 pandemic has mounted high pressure on the medical sector and enforces medical systems to find a solution to minimize the direct connection between medical staff and patients. Consequently, UOI technology has played a main role in this matter. As it provided an efficient, high-quality tool to help medical staff and reduce the direct connection with patients. UOI was employed to collect, analyze, and transmit data over the web in real-time. However, the UOI as any wireless equipment is prone to cyber security attacks. Possible cyber-attack on UOI puts the patient’s life in jeopardy. This proposed project aims to investigate the cyber security attacks on UOI by developing a machine-learning model using the most updated and universal public UOI dataset (WUSTL EHMS 2020 Dataset). Consequently, WUSTL EHMS 2020 Dataset was created using a real-time Enhanced Healthcare Monitoring System (EHMS) tested. It has 160,000 records and consists of 44 features where 35 features are network flow metrics, 8 patients’ biometric features, and one feature for the label. We have relied on the use of the latest technologies, programming languages, and use of the programming language in Python, as well as real data.
Keywords: UOI, machine learning, security, healthcare dataset.
1. Introduction
The Universal Object Interaction (UOI) is transforming our lives and workplaces by allowing more people and terminals to connect to everything they need. In other words, the UOI is the concept of connecting any device (as long as it has an on/off switch) to the internet and other connected devices. The Universal Object Interaction (UOI) is a vast network of interconnected things and people that gather and exchange data on how each component of the UOI works. From smart microwaves that cook meals for the exact amount of time set to self-driving automobiles with intricate sensors that identify items in their route, the Universal Object Interaction encompasses a vast spectrum of objects of all shapes and sizes. Fitting vesture devices that track a person’s pulse rate and daily steps then utilize that information to create exercise routines that are specific to that person. Footballers can use an app to track time and speed they can run to save the information for future training. Real-time data can be accessed through terminals and servers. As a result, in open WIFI situations, security and privacy are crucial to safeguard users from various forms of malice [18].
Significant technological and internet revolutions have taken place in recent decades. This significant advancement has resulted in the creation of the Universal Object Interaction, which can effectively support and facilitate a variety of functions in the medical field, such as real-time patient assessment and monitoring, diagnosis, and the provision of various treatment solutions by automatically assessing the available data. The UOI (UOI) and its interconnected technological capabilities have taken on new and sophisticated dimensions, making them ideal for improving medical procedures and, as a result, achieving nimble, fully intelligent systems.. Because new peripherals are seen in the healthcare industry, the UOI medical data has been rapidly improving. Treatment activities and good healthcare outcomes can be facilitated by introducing effective technological solutions for smart decision-making [17].
Machine learning models are usually applied in actualizing different functions like diagnosis using medical techniques and guiding subsequent therapies and treatments. However, given the increased availability of large volumes of data for patients’ medical care characterized by significant complexities, dimensions, and other dynamics, the existing machine learning models’ proficiency may not undertake the assigned systemic functions adequately and effectively as required. In this case, advanced classifications of techniques and majorly advanced models are required to provide effective and viable intervention. The introduction of more agile models can assist in handling larger volumes and solve highly complicated issues. Moreover, it helps reduce the rate of total overreliance on the healthcare workers and, in the long term, helps in the reduction of costs involved in care delivery services [12].
Despite the positive outcomes related to the medical technology UOI-based systems, they are highly vulnerable to different security lapses, creating negative outcomes. In these cases, they are prone to malicious cybercrime attacks. It is a severe problem for medical and healthcare managers to prevent their networks from probable attacks. Specifically, systemic lapses prevent crucial data, including clients’ information, from malicious and unauthorized access. Overall, there are more severe cybersecurity challenges than ever hence the need to have a strong systemic machine-learning model to prevent malicious intrusion for the UOI.
This project aims to develop a secure machine-learning model that can prevent UOI intrusion. This proposed model will have multi-faceted competencies for detecting both internal and external attacks. The specific objectives include:
- Ensure the security of patient information within UOI.
- Collection and analysis of data regarding the combination of biometrics. Network flow for developing effective analysis of intrusion.
- Assessment of the possible UOI attacks.
- Developing a machine learning system to improve UOI security in various manners.
The contributions of this project are as follows:
- Given the agility of the emerging technologies operating under the support of the internet in the wake of the increased population of patients in healthcare facilities with various health complexities, it is crucial to guarantee quality and effective care. This project is motivated by the need to have efficient healthcare systems that adequately cater to patients’ needs. This project is significant as it provides advanced solutions for utilizing the available technology to optimize healthcare delivery. Furthermore, it adds to the existing literature on medical technology integration.
- By expanding on the proposed model, the project aims to Existed public dataset will be used for training and testing. The project will be utilizing a publicly accessed data set as the big data platform for the scope of the implementation. The proceeding work plan of the research include; Segment 2 describing the associated literature review. Segment 3 presenting and clarifying the highlighted approach. Segment 4 provides the results sections. Finally, segements 5 and 6 mentioned the discussion and conclusion of the study.
2. Related Literature
The development of expert system/machine learning models for the universal object orientation has been significantly studied from different prompts. Therefore, comprehensive information regarding the related technological techniques and applications was covered in this section. The available literature provides an in-depth understanding of machine learning proficiencies, which is crucial for effective modeling.
The work done by Bahlali [3], reported that the system attacks technique had been significantly advancing in recent years. This study justifies the need to conduct a study and identify the agile and stronger machine learning-based models ideal for preventing the possible sophisticated systems of intrusion detection and preventing the possible detrimental impacts. The anomaly detection-based models have the advantage of detecting any form of potential unseen attacks in the system. The researcher recommends using the UNSW-NB15 dataset, which is ideal for detecting the current system complexities using various techniques of machine learning like the deep learning technique known as the artificial neural network and others like logistic regression [3].
Khraisat et al. [11] explored the novel ensemble for system detection of hybrid intrusions to detect UOI attacks. The researchers confirmed that despite the consistent efforts of UOI evolution to create substantial effects and suitable impact on various systems, cybercriminals’ interference has been inevitable with a high prevalence of malicious attacks on the systems. Additionally, it is highly challenging to provide the ideal form of protection to the systems’ infrastructure using the traditional or outdated techniques of detecting intrusions due to the diverse range of UOI devices in the wake of technological advancement. To ensure the effective protection of the systems, a novel aggregate system of perimeter intrusion detection is highly recommended by integrating a one-level Support Vector Machine classifier (SVM) and the C5 model classifier [11]. This particular technique has high accuracy in detecting possible intrusions and daily attacks with low rates of false alarms. The study findings’ reliability and accuracy are advanced by the use of Bot-UOI data sets to assess the detection proficiency for various types of possible system intrusions and attacks.
In the further evaluation of this critical aspect of system intrusion, Hady et al. [8] investigated the use of medical and network raw facts to develop a reliable intrusion detection system in healthcare. The researchers argue that UOI is highly influential in the medical sector and adequately facilitates inter-related functions, including remote monitoring of patient information and providing effective diagnostic solutions for different health complications. The researcher further explores the risks involved, including the increment of human casualties, especially those in emergencies resulting from data interference. These information sets are highly readable as they capture various dynamics involved and provide the basis for actualizing agile models, which can effectively manage the identified issues. Machine learning has a high capability of guaranteeing effective detection in case of system intrusion because of the high dynamics and dimension of the medical data [8].
However, the available intrusion detection systems available in the healthcare systems categorically rely on either the patient biometrics or network flow metrics to establish their specific datasets. In this case, Hady et al. [8] recommend combining both patient and network metrics to set up a reliable and accurate detecting intrusion system. These findings are reliable as they were established by assessing 16 thousand data records of various attacks. Through the application of different machine learning techniques to facilitate functions like testing and training the available datasets against the prevalent forms of attacks. The outcomes obtained confirm that the system’s level of performance significantly increased, which confirms the high level of robustness for the recommended system of detecting the possibility of intrusions and attacks. Therefore, such a concept can be effectively incorporated when improving the available machine learning models as an ideal strategy for enhancing the UOI functionality.
Hodo et al. [9] did the UOI network threat analysis based on the artificial neural network intrusion detection system. Using the internet packet traces, the researchers comprehensively assess artificial neural networks’ ability to thwart the system attacks referred to as the distributed denial of service. The findings report a high accuracy rate of about 99.4% for the artificial neural network technique in detecting the possible denial of service attacks. In pursuance of the network stability, Pourghasemi et al. [19] examined the two-layer dimension reduction and two-tier classification model to detect anomaly-based forms of intrusion in the UOI backbone networks. This novel model for detecting intrusion was strategically designed to detect various malicious issues, including the remote to the local and user to root forms of attacks. Using the experimental findings, the datasets used indicate that this particular model significantly outperforms the previously designed models to detect the user to root and remote to local forms of attacks. Another studied intrusion detection systems for fog computation and UOI-based logistic systems using smart data. In this scenario, the researchers recommend developing lightweight anomaly-oriented intrusion detection systems to manage this problem adequately. The overall implication, in this case, is that smart data stands out as a reliable concept for effective detection of any possible intrusion. Its reliability is increased by even detecting silent attacks like the botnet in the highly vulnerable UOI systems [17].
The literature review reveals comprehensive information and facts regarding machine learning on the UOI by assessing inter-related specific issues and concepts. The outcomes indicate the need for data security and system intrusion prevention when developing an advanced machine-learning model for the UOI. Given the availability of reliable technology-based information, this study will have the implications of advancing the quality of medical care service delivery, which in turn has the impact of boosting the patients’ health status and welfare as the core objective of professional practice in medicine by safeguarding data, which is the basis of all the operations.
3. Methodology
The suggested method is divided into four key parts (Figure.1), with the output from each step serving as the input to the next step in the process.
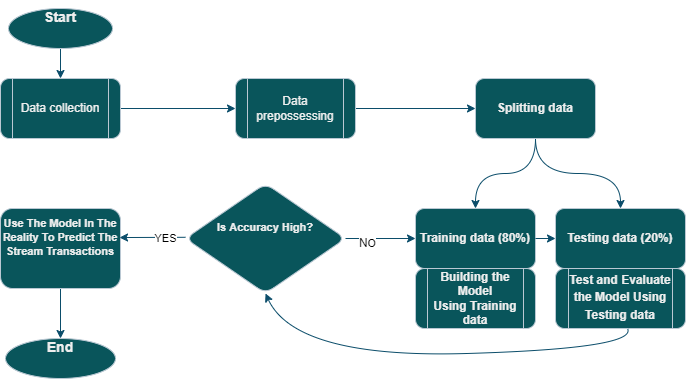
Figure 1. Suggested method.
This section covers the experimental setup, including the development environment, the selected UOI dataset, experimental design, and dataset analysis. Additionally, it covers theoretical discussions about the algorithms and measurements used in this project.
a). Dataset
This project’s dataset is the WUSTL-EHMS-2020 for Universal Object Orientation (UOI) Cybersecurity Research. It was created using a real-time Enhanced Healthcare Monitoring System (EHMS) tested. It contains160000 records and consists of 44 features, where 35 features are network flow metrics, eight patients’ biometric features, and label feature. The data is labeled using the source MAC address, with the subsets with the attacker device MAC ( Media Access Control)addresses labeled as 1 and the rest as 0. Man-in-the-middle attacks, such as spoofing and data injection, are included in this dataset. The spoofing attack aims to sniff packets between the gateway and the server, compromising the patient’s data confidentiality. The data injection attack modifies packets on the fly, compromising the integrity of the data.
b). Data Preprocessing
Data preprocessing is a process for preparing raw data used in a machine-learning model. Because datasets contain noise, are in an unsuitable format, and are unbalanced, with normal samples accounting for around 88 percent of the data, data preprocessing is considered to be necessary and is implemented using the following step (Figure 2):
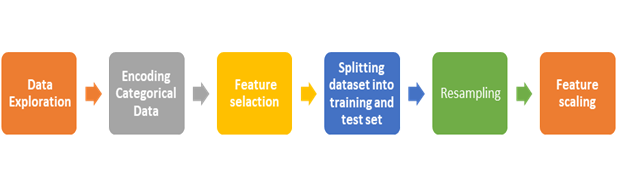
Figure 2. Data preprocessing.
c). Data Exploration
The WUSTL-EHMS-2020 dataset is highly unbalanced as illustrated in Table 1, the number of attack samples forms 12.5% of the total data, whereas the normal sample forms around 87.5% of the total data.
| Measurement | Value |
| Dataset size | 4.4 MB |
| Number of normal samples | 14,272 (87.5%) |
| Number of attack samples | 2,046 (12.5%) |
| Total number of samples | 16,318 |
Table 1. Dataset Statistical Information.
d). Encoding Categorical Data
Encoding categorical data is a process of changing categorical data into integer format. Therefore, the data with changed categorical values can be offered to the models to provide and improve the predictions [15].
e). Feature selection
When generating a predictive analysis, feature selection is a process for reducing the number of input variables. In order to lower the computational cost of modeling while also improving the model’s efficiency, it’s critical to limit the amount of input variables currently in use.
f). Splitting dataset into training and test set
For accurate calculation of the ML models’ execution, the dataset must be bootstrapped into training and testing models with a distribution of 80% and 20%, respectively.
g). Resampling
As presented in Table 1, the UOI dataset is highly unbalanced, where the number of normal samples is 88 percent of the data. SMOTE, an over-sampling method, to stabilize the dataset during the training phase.
h). Feature scaling
Feature scaling is deemed necessary for the machine learning algorithms that compute distances amidst data. Since the variety of the underlying values of raw data differs broadly, within certain machine learning algorithms, objective functions do not operate correctly devoid of the normalization. Feature scaling the target value is deemed significant in regression modeling since it aids in making it easy for the model to learn as well as comprehend the problem.
i). Machine Learning Models
● Random forest (RF)
Random forest involves selection of decision trees constructed from a subdivision of the dataset chosen at random. It then assemble all the tally from these decision trees and chooses the best class for the test attributes [1]. This procedure may be used to assign the greatest number of characteristics for the optimal split in the Trees for the network and aggregated set of features at 18. To build the final result, the Random Forest Algorithm often includes the output of numerous (randomly constructed) Decision Trees. RF regression trees, which are generally unpruned to provide strong predictions, may be used to build prediction models in the RF approach [14]. Oblique RF outperforms traditional deep axis-aligned splits in displaying separation of distributions at the coordinate axes with a single multivariate split [14].
● K-Nearest Neighbor (KNN)
The K-NN method often assumes that the existing relatedness between the new case and the related available instances puts the new case into a classification that is nearly equivalent to the existing classifications [6]. Moreover, the K-NN method retains all available data and categorizes new data locations based on similarities; therefore, when new data emerges, it may be categorized into a decent suite categorization using the K-NN algorithm/procedure [20]. As a result, K-NN technique may be used to solve issues like regression and classification.
● Support Vector Machine (SVM)
SVM is a duplex categorization technique that excels at dealing with exciting occurrences in a dataset. It works by tracing a hyper-plane between both sets of the data set’s servers, which is the longest distance between them [10]. Furthermore, the size of the hyperplane is highly dependent on the number of features available. The underlying hyperplane is effectively a line [7] when the number of input features is two. Support vectors, which are data points that are much closer to the hyperplane [10], establish the location and direction of the hyperplane. The classifier’s margin is maximized by using these support vectors, and the position of the hyperplane that aids in the formation of the classifier is minimized by removing any of the support vectors.
● Artificial neural networks (ANN)
Artificial Neural Networks are complicated classifiers inspired by the brain; they use neurons that take inputs and have an internal state that creates the output when combined with the input [7]. The three ‘layers’ in these networks are the input , hidden, and output , however a network might have several hidden layers. Each neuron in one layer is either randomly linked to the following layer up to the output layer, or each neuron in the next layer is connected to all the others.
● Decision Tree (DT)
A Decision Tree is a machine learning algorithm that works by extracting features from instances in a training dataset and then building an ordered tree based on the recovered features’ values [5]. In DT, there are two nodes: the Decision node and its accompanying Leaf node. The creation of the DT begins at the tree’s root node [5]. Various criteria, such as the Gini index and information gain, are used to select the feature that best divides the tree. The induction and inference processes are carried out by DTs.
● Logistic Regression (LR)
Because a logistic regression (LR) technique can predict the likelihood of a certain instance belonging to a specified class, it is commonly used in classification tasks like intrusion detection and spam filtering. The implementation of LR is predicated on specific assumptions, such as that in binary LR, the variables must typically be binary, and the intended outcome is represented by factor level 1[19]. Within the model, there should be no multiple collinearity, which means that the independent variables should be independent of one another. Furthermore, there should be significant variables included in the model, as well as a viable choice of a high sample size for the LR.
● XG Boost
It usually assists in the development of machine learning procedures within the Gradient Boosting structure [16]. It provides GBDT, a parallel tree-boosting algorithm that solves a variety of data science issues quickly and reliably.
● Ensemble methods
Ensemble approaches integrate many base models to create a single best prediction model. These strategies are thought to be suitable for regression and classification, since they reduce bias and variance in order to improve model accuracy [20]. Bagging, boosting, and stacking are the three primary forms of ensemble approaches. Bootstrapping aids in the randomization of the selection process, while aggregation is accomplished by including all potential prediction outcomes and therefore randomizing the result [2].
4. Results and Discussion
This section summarizes the outcomes of the different machine learning on which the dataset was trained, validated, and then tested.
The selected dataset is divided into three main parts: training dataset, validation dataset, and testing dataset. We have applied different classification algorithms. The algorithms that were applied included Random Forest, KNN, SVM, ANN, and Logistic Regression, Decision Tree, XGBoost, and Ensemble Learning. Before employing machine-learning models on a dataset in any area, the most critical step is preprocessing data since the ML technique generates better results when preprocessed data is used. The main problem with the selected dataset was that it was unbalanced. To address this, we resampled the data using the SMOTE approach, which balanced both of our dataset’s normal and attacked classes. Both classes 1 and 0 now have the same representation. Figure 3 illustrates graphic representation of dataset before and after use of SMOTE( Synthetic Minority Oversampling Technique).
In addition, a feature engineering process is used to select and transform the most important variables from raw data using domain expertise (Figure 4). The purpose of the feature engineering and selection method is to make machine learning (ML) algorithms work better.
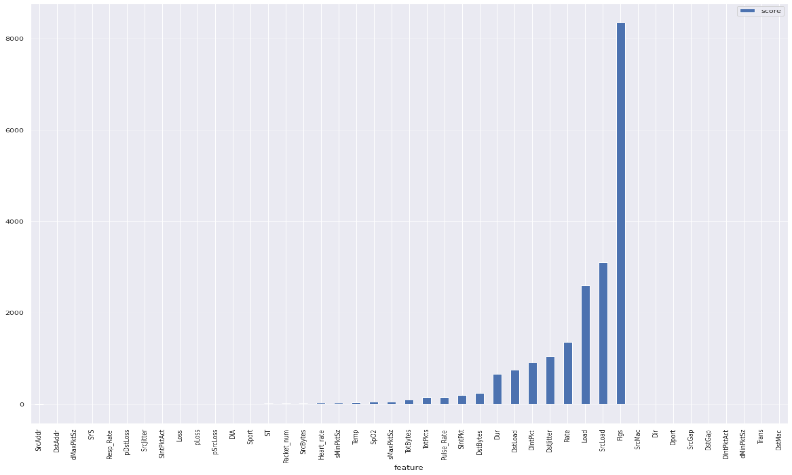
Figure 3. Feature engineering.
Figure 5 presents the feature selection (unsupervised selection and supervised selection) results, different features having low or zero values, indicating that they do not contribute to the machine-learning model for prediction. Therefore, we only feed the model with the important features, which enhance the model’s performance .Supervised selection features rely on availability of data to recognize the pertinent features for best achievement on goal of the supervised model. This feature may be divided into filter, intrinsic and wrapper. Unsupervised feature selection draws inferences from datasets without labels. It is best used if one wants to identify patterns but is knowledgeable of what to look for.
Figure 4. The graphical representation for the feature’s selections.
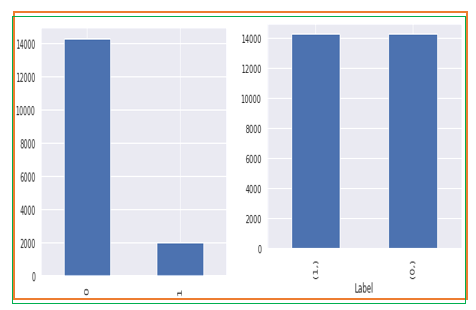
Figure 5. Data unbalanced and balanced.
The validation data set, which is not part of the training data set, demonstrates how effective the model is to generalize. The presented models are evaluated using the validation dataset. To some extent, cross-validation (resampling method which tests and trains a model on different iterations ) accuracy is lower than training accuracy. However, in certain models, the training and validation sets are almost close in accuracy. Figure 6 illustrates that KNN works well in the sense that training and validation accuracy are nearly identical at a specific stage, while logistic regression works, and this pattern is continuous. This certify that the validation data hardly from the training data set and that its accuracy is the same as that of the training data set, indicating the success and validation.
After completing a number of tests for analyzing the behavior and comprehending the efficacy of the classifier using Confusion Matrix, the performance evaluation result was produced from the models. The confusion matrix’s output is divided into True Positive, True Negative, False Positive, and False Negative categories for the binary classification.
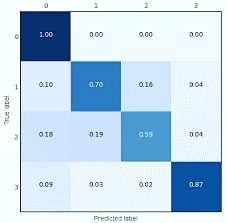
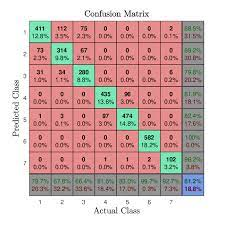
Figure 6. Confusion matrix of Random Forest
Above diagram represents a confusion matrix for random forest and K-NN models.
Confusion matrix for Random Forest is very easy to generate in a case of 2 classes.
An evaluation metrics quantifies the performance of a predictive model. Some of evaluation metrics that were used include presion, accuracy, and recall.
This research implemented eight Machine Learning methods and compared them based on their execution using accuracy [(Total Positives + Total Negatives) divided by the total number of a dataset( positives + negatives)] and AUC(Area Under the Curve) metrics. The Accuracy
Through comparison of the number of properly categorized attacks and the normal occurrences of the total number of cases, accuracy indicates the model’s overall success. Therefore, the Random Forest and KNN Classifiers outperformed the other two classifiers (Support Vector Machine and Artificial Neural Networks)(Figure 7) with a result of more than 95%. In addition to the XGB and Ensemble Classifier from the second group, XGB provides parallel tree boosting (Figure 8). Between the two groups, ensemble learning has the best accuracy in the second group where the voting ensembles works by merging the predictions from multiple models. It can be used either for categorization or regression. In the case of classification, the predictions for each label are totalized and the label with the majority tally is predicted.
While the ROC(Receiver Operating Characteristics) curves, AUC is a real number ranging from 0 to 1 that represents the area under the ROC curve.
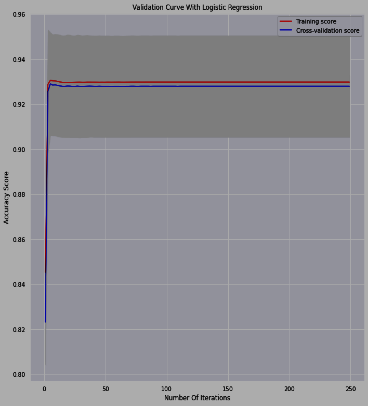
Figure 7. L cross-validation curve.
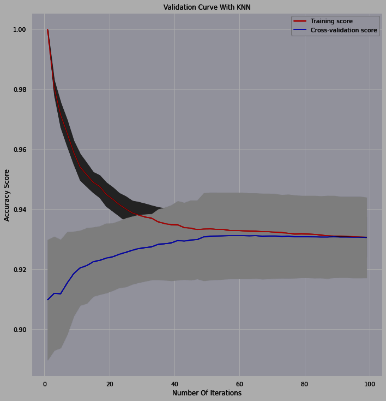
Figure 8. K-NN, Lr cross-validation curve.
The ROC curve is a clear way to evaluate the trade-off between sensitivity(ability to test for a true outcome for example patients with a disease) and specificity(ability to test for a false outcome for example patients without a disease). The receiver operating characteristics (ROC) is commonly shown as a graph plotted against the confusion matrix TPR ( True Positive Rates) and FPR(False Positive Rates) for various threshold settings. The Area Under the Curve is referred to as the AUC, and it should have a greater numerical value to be considered better. Therefore, the results below indicated that the Ensemble Learning model, Random Forest model, ANN, and Decision Tree have a high area under the curve and this means that they are prime and able to classify between the normal and attack classes.
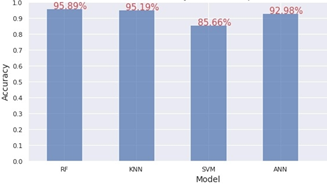
Figure 7. Test accuracy score comparison group 1.
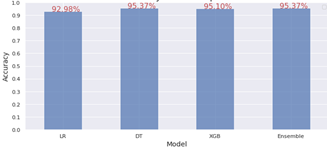
Figure 8. Test accuracy score comparison group 2.
5. Conclusions
While the UOI technology is still in its early phases of development, its integration into the medical sector has significantly improved the delivery of medical care and the care provided to patients. A secure data-driven medical care environment will most likely aid in making accurate treatment decisions for patients, allowing doctors to accurately identify the patient’s health status and decreasing response times in an emergency room setting. Despite the fact that automating the healthcare monitoring process will boost operational efficiency, there are hazards that might develop throughout the deployment phase that must be considered (e.g., insecure data channels, information leakage, and unauthorized access to medical devices).
These difficulties, when paired with tight restrictions, may serve to stifle the development of both UOI networking and data solutions in the future. Specifically, in this examination, we establish a secure machine-learning model that can prevent UOI intrusion to maintain the integrity and privacy of patient data. The chief objectives of this project have been successfully achieved. . Eight models have been implemented: the ANN, KNN, SVM, and RF, DT, LR, XG boost, Ensemble classification models, where each model has been assessed through analyzing numerous parameters. Through adopting a machine-learning system dataset and using the selected dataset with the machine learning models, evaluating the detection accuracy for each model, and discussing the obtained results. The Random Forest in the first group outperformed the other models with an accuracy of 95.89 %, according to the results. The ensemble classifier scored 95.37 % accuracy in the second group of models. However, future work will require utilization of the data set that contains more attacks since the e dataset used within the project and machine learning models contains only one attack, which is the main in the middle in the network layer. Therefore, further study on the utilization of Hybrid data sets that contain more attacks to enhance security in UOI Against various attacks.
6. References
- Ali, J., Khan, R., Ahmad, N., and Maqsood, I., “Random forests and decision trees,”International Journal of Computer Science Issues, vol. 9, no. 5, pp, 272, 2012.
- Ardabili, S., Mosavi, A., and Várkonyi-Kóczy, A. R., “Advances in machine learning modeling reviewing hybrid and ensemble methods,”In International Conference on Global Research and Education, Springer, Cham, pp. 215-227, 2019.
- Bahlali, A. R., “Anomaly-Based Network Intrusion Detection System: A Machine Learning Approach,” 2019.
- Cai, J., Luo, J., Wang, S., and Yang, S.,“Feature selection in machine learning: A new perspective,” Neurocomputing, vol. 300, pp, 70-79, 2018.
- Charbuty, B., & Abdulazeez, A.,“Classification based on decision tree algorithm for machine learning,” Journal of Applied Science and Technology Trends, vol. 2, no. 1, pp. 20-28, 2021.
- Gazalba, I., and Reza, N. G. I.,“Comparative analysis of k-nearest neighbor and modified k-nearest neighbor algorithm for data classification,”. 2nd International conferences on Information Technology, Information Systems and Electrical Engineering, 294-298, 2017.
- Güven, İ., and Şimşir, F.,“Demand forecasting with color parameter in retail apparel industry using artificial neural networks (ANN) and support vector machines (SVM) methods,” Computers and Industrial Engineering, vol. 147, pp. 66-78, 2020.
- Hady, A. A., Ghubaish, A., Salman, T., Unal, D., & Jain, R., “Intrusion detection system for healthcare systems using medical and network data: A comparison study,” IEEE Access, vol. 8, pp. 106576-106584, 2020.
- Hodo, E., Bellekens, X., Hamilton, A., Dubouilh, P. L., Iorkyase, E., Tachtatzis, C., and Atkinson, R., “Threat analysis of UOI networks using artificial neural network intrusion detection system,” International Symposium on Networks, Computers and Communications, 1-6, 2016.
- Kalantar, B., Pradhan, B., Naghibi, S. A., Motevalli, A., and Mansor, S., “Assessment of the effects of training data selection on the landslide susceptibility mapping: a comparison between support vector machine (SVM), logistic regression (LR) and artificial neural networks (ANN),” Geomatics, Natural Hazards and Risk, vol. 9, no. 1, pp. 49-69, 2018.
- Khraisat, A., Gondal, I., Vamplew, P., Kamruzzaman, J., and Alazab, A. “A novel ensemble of hybrid intrusion detection systems for detecting Universal Object Interaction attacks,” Electronics, vol. 8, no. 11, pp. 1210, 2019.
- Kim, G. H., Trimi, S., and Chung, J. H., “Big-Data Applications in The Government Sector,” Communications of the ACM, vol. 57, no. 3, pp. 78–85, 2014.
- Lebdaoui, I., and El Hajji, S., “Managing big data integrity,” International Conference on Engineering & MIS, Agadir, Morocco, 2016.
- Liu, Y., Wang, Y., and Zhang, J., “New machine learning algorithm: Random forest,” International Conference on Information Computing and Applications, Berlin, Heidelberg, pp. 246-252, 2012.
- McGinnis, W. D., Siu, C., Andre, S., and Huang, H., “Category encoders: A scikit-learn-contrib package of transformers for encoding categorical data,” Journal of Open Source Software, vol. 3, no. 2, pp. 501, 2018.
- Mo, H., Sun, H., Liu, J., and Wei, S.,“Developing window behavior models for residential buildings using XGBoost algorithm,” Energy and Buildings, vol. 205, 2019.
- Nath, A., “Big Data Security Issues and Challenges,” International Journal of Innovative Research in Advanced Engineering, vol. 2, no. 2, pp. 15-20, 2015.
- Oorschot, V., C, P., Smith, and W, S., “The Universal Object Interaction: Security challenges,” IEEE Security & Privacy, 2019.
- Pourghasemi, H. R., Gayen, A., Park, S., Lee, C. W., and Lee, S.,“Assessment of landslide-prone areas and their zonation using logistic regression, logitboost, and naïvebayes machine-learning algorithms,” Sustainability, vol. 10, no. 10, pp. 36-97, 2018.
- Zhang, Y., Cao, G., Wang, B., and Li, X.,“A novel ensemble method for k-nearest neighbor,” Pattern Recognition, vol. 85, pp. 13-25, 2019.
 write
write